A Basic Guide to Transaction Isolation
Nuances and implications of ambiguous database transaction isolation levels

Search for a command to run...
Nuances and implications of ambiguous database transaction isolation levels
Tips for Efficiently Managing Nulls Using Spring's Named Parameter Binding

A guide to the features of multi-active and multi-region systems

Creating a user-defined composite Money type in CockroachDB

Implementing transaction timeouts in CockroachDB with Spring Boot and JPA/Hibernate

Using 1PC pattern with Spring and CockroachDB

ACID transactions are implemented differently in databases and provide different runtime characteristics towards applications. It's mainly manifested in terms of when different operations are blocked from proceeding or a transaction is forced to retry. That is, if the isolation level is indeed serializable, which is not always the case. Not all databases provide true ACID guarantees and that presents a problem if you are dependent on it.
The "I" part in ACID stands for serializable isolation, which means that a database that formally claims to support ACID needs to provide the highest isolation standard in SQL - serializable. Serializable isolation guarantees that even though transactions may execute in parallel, the result is the same as if they had executed one at a time, without any concurrency.
Executing transactions serially would lead to the same result, but it would also destroy any performance aspirations. Concurrent execution is a must-have. One way to look at it is that it's a magic show hosted by the database, giving the illusion to clients they are the exclusive users of the database, completely free from interference from others.
(image from: https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/)
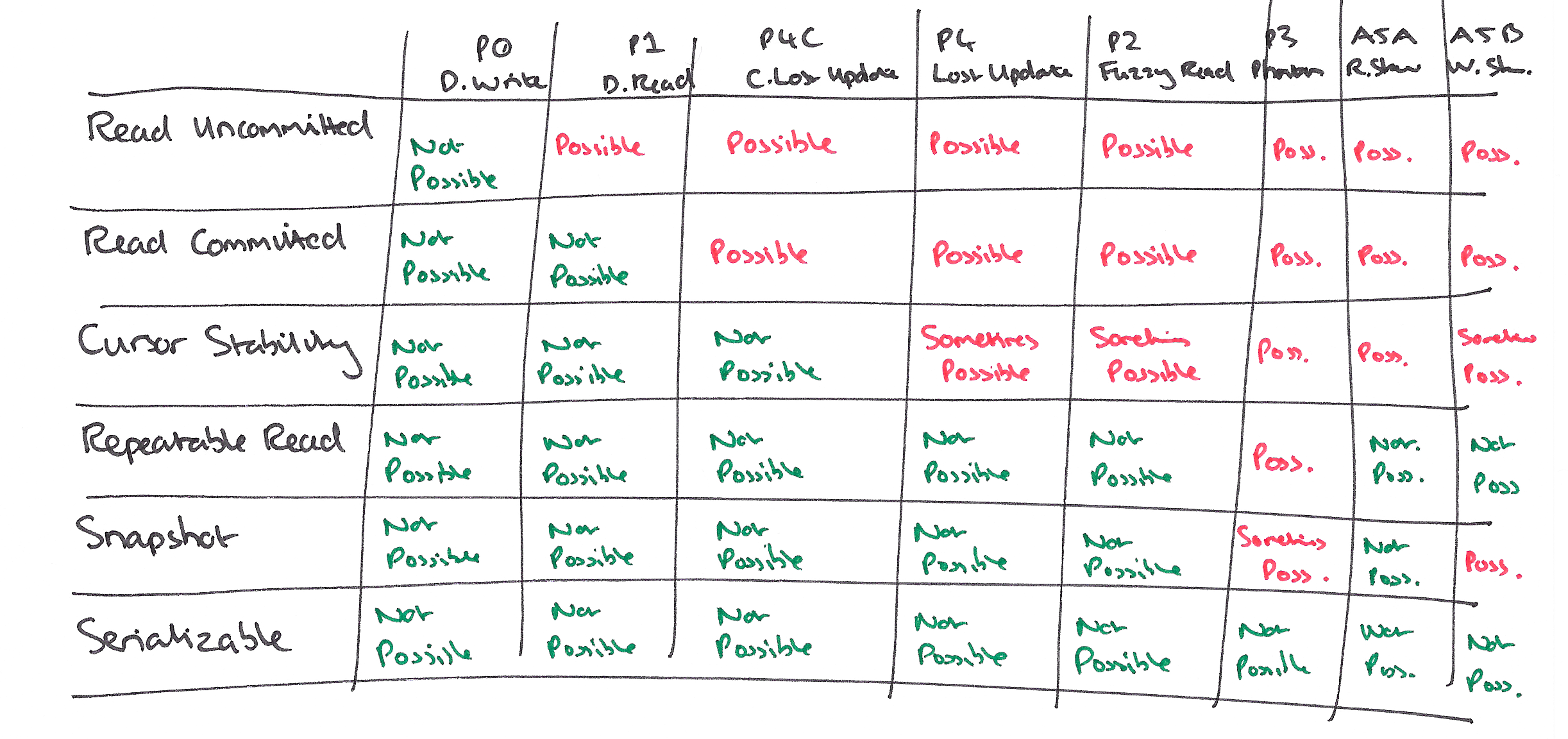
Isolation levels are however confusing and ambiguous, in particular for distributed databases where you don't have a single time source. Not only are isolation levels difficult to understand but can also mean different things. Serializable in Oracle, for example, actually means Snapshot (which is weaker) and Repeatable Read in PostgreSQL means snapshot (which is stronger). Snapshot also permits write skew (A5B), which Repeatable Reads does not. Then we have Oracle Read Consistency, which is like Read Committed, only stronger by advancing the transaction timestamp for each SQL statement.
This ambiguity presents a real challenge for application developers and architects. They are tasked to figure out when a given isolation level is sufficient for correct execution. It also makes it more difficult to think in terms of portability between databases when the behaviour is different. One piece of advice is that unless you are 100% sure of what anomalies business rule invariants are exposed to, then go for a higher level of isolation.
Related Resources:
http://www.bailis.org/blog/understanding-weak-isolation-is-a-serious-problem/
http://martin.kleppmann.com/2014/11/25/hermitage-testing-the-i-in-acid.html
https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/
The goal of transaction isolation is to find a good balance between safety and performance for concurrent transactions. A database should allow concurrent access to data while still being safe, meaning that concurrent operations that happen to interleave, should not observe intermediate state, overwrite other transaction writes or violate invariants guarded by constraints. It's the database being liberal and conservative at the same time.
A higher isolation level reduces and even eliminates most known read/write conflict anomalies, at the expense of performance and rollbacks on contended operations. Performance is increased and transient errors are reduced by lowering the isolation level, effectively requiring less coordination and planning effort by the database to guarantee safe, concurrent execution. It depends on the database implementation though, and in some cases, the difference in performance is small for non-contending operations.
The main downside of lowering isolation is that applications become more exposed to read-write phenomena (anomalies) that may cause data loss or corruption in the worst case. These types of errors are quite difficult to track down and test for.
The lowest isolation level is Read Uncommitted (RU) meaning basically that all (most) bets are off. It allows dirty reads (P1) where transaction T1 is allowed to read transaction T2:s writes that haven't been committed yet. Read Uncommitted must prohibit dirty writes (P0) though, where T1 would modify T2:s write before it has committed.
The highest ACID isolation level is serializability which means transactions are not exposed to any read/write anomalies. A client can safely read and write without having to worry about other transactions possibly performing the same operations. The database will guarantee that no client will ever observe any inconsistent state and that all invariants will be preserved at commit.
In between you have all the rest. Anomalies can either be permitted or prevented by using ANSI SQL isolation levels, or something even higher like strict serializability or linearizability (external consistency).
Common anomalies include:
Dirty write (P0)
Dirty read (P1)
Fuzzy read (P2)
Phantom (P3)
Strict Phantom (A3)
Lost update (P4)
Cursor lost update (P4C)
Read Skew (A5A)
Write Skew (A5B)
Surprisingly enough, the default isolation level in most modern databases is read committed (RC). It is a fundamentally unsafe isolation level exposed to lost updates (P4) and more. Still, many applications are using it and seem to work fine most of the time.
But how can you be sure you will not be the next Bitcoin exchange or e-commerce site that gets exploited by weak isolation? Trying to navigate through these things is not far from trying to beat classic Minesweeper.
Modern lock-free MVCC databases (and others) like Oracle and PostgreSQL default to Read Committed (RC). As MVCC databases, they also support snapshot isolation (SI) which is a slightly weaker model than serializable.
SI does not use locking, which is sort of the point with MVCC, but instead every transaction operates on an isolated snapshot of committed data whose values are not visible to other transactions unless the transaction commits.
SI sorts in somewhere between read committed and serializable (Berenson and Adya). It prevents P4 (lost update) by applying a first committer wins policy and like Repeatable Read (RR) it prohibits P0, P1 and P2. It prevents a special version of P3 called A3 (Phantom) that RR allows, but allows A5B (write skew) that RR prevents. Write skew is when two concurrent transactions are writing based on reading a data set which overlaps what the other is writing.
PostgreSQL (since 9.1) implements serializable isolation on top of SI, called serializable snapshot isolation or SSI. It prevents A5B (write skew) by forcing conflicts through either promoting reads to writes or by analyzing dependency cycles in transactions.
If you are not already confused at this point, then congratulations. These conditions and more are outlined in far more detail in the A Critique of ANSI SQL Isolation Levels paper.

Cockroachdb only implements serializable isolation, which narrows down the options. It gives peace of mind if you are concerned about read/write anomalies.
ACID transaction isolation levels are ambiguous and tricky to grok. Most modern databases implement transaction isolation differently and often have weak defaults where applications need to opt-in for higher isolation. In CockroachDB, the only choice is serializable which is the highest level in the SQL standard.