



Building a CockroachDB Data Pipeline
Using a micro-batch oriented data pipeline tool with CockroachDB


Background
One common challenge is how to migrate or copy data from one database to another in a seamless and stream-oriented fashion. Either as a one-off migration project or continuously as part of a development process to keep an offline copy in-sync for the purpose of smoke testing, load testings or whatever.
These interconnects or data pipelines can be both simple and more sophisticated. For example, to feed online system data to downstream analytical systems, materialized views for caching, populate audit logs and so forth.
There is typically more patterns out there than there is tooling to support data migrations which has to do with the fact that each project is unique. However, most database product features and 3rd-party tools typically build on the same type of primitives. Either that being change-data-capture (CDC), database dump files, CSV import/exports, SQL exports/imports etc.
There are still plenty of great tools to build quite sophisticated data pipelines with a fairly low effort, like Apache NiFi, Attunity, Striim, Debezium and more. For a tutorial of Nifi, see this project in GitHub created by Chris Casano.
In this post, we will outline yet another approach that blends well into the data ingress/egress capabilities of CockroachDB with focus on simplicity.
Introduction
Meet Roach Batch - which is a simple data pipeline and migration tool for CockroachDB based on micro-batching and open protocols. It's fully open-source available under the MIT license and free to use at your own risk.
Roach Batch can be used to both ingest and extract data between CockroachDB and another database or cloud storage service for the purpose of data migration or cluster to cluster streaming.
It uses a fairly simple approach that doesn't involve any complicated data transformation steps. Instead, there's an assumption that the table schemas are matching quite close and that a CSV export can be easily mapped to a target schema.
Sometimes the reality is more complicated where intermediary steps to merge/split or consolidate data in different steps is needed. This is not the right tool for that type of requirements.
How it works
Roach Batch operates at individual table level where you submit an independent one-off batch job (through its REST API) for each table or file to be either ingested or extracted between a source and a target.
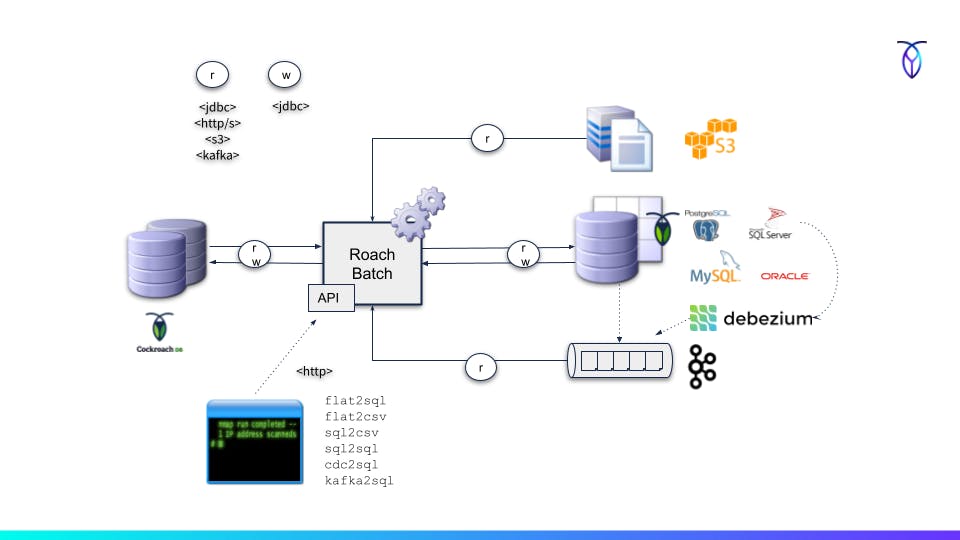
One option is to use Change Data Capture (CDC) either through CockroachDB's Kafka or Webhook sink and generate batched UPSERT statements based out of these feeds. That effectively provides a cluster to cluster streaming pipeline scoped to individual tables (the kafka2sql and cdc2sql jobs).
Another simpler option is to pass a series of keyset pagination queries to either PostgreSQL, Oracle, MySQL, SQL Server or CockroachDB and write each batch straight to a target database using UPSERTs or INSERTs (the sql2sql job).
Last example is a fixed-width flat file import from a cloud storage bucket. CockroachDB currently only supports delimited files (CSV) so if you have a fixed-width file you need to convert it first. Using this method however, you just point the IMPORT INTO command to the flat2csv REST endpoint which in turn reads from the cloud storage bucket and maps the fixed width file using a custom schema.
Pipeline Options
Examples of different pipeline options:
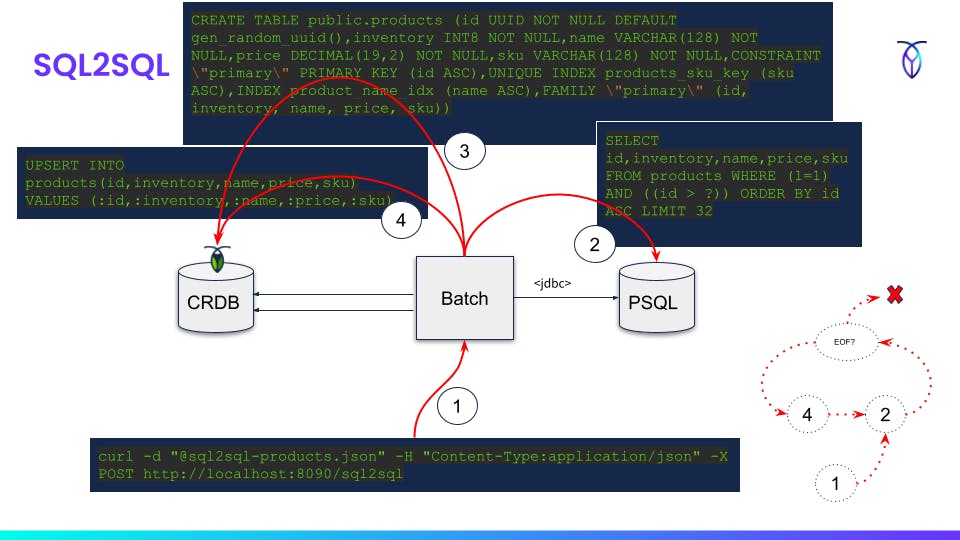
- Submit job manifest to REST API
- Source database query based on manifest (keyset pagination)
- Optional DDL for target database
- UPSERT of each batch read in step 2 into target database
- Repeat
2->4until no more rows
Example:
curl -X GET http://localhost:8090/sql2sql/form?table=products > sql2sql-products.json
curl -d "@sql2sql-products.json" -H "Content-Type:application/json" -X POST http://localhost:8090/sql2sql
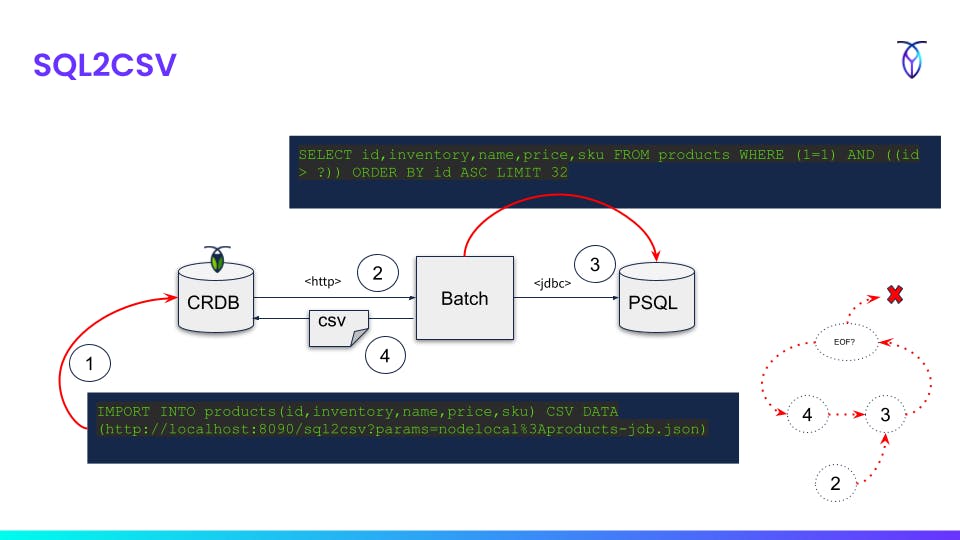
- Execute
IMPORT INTOcommand and point out REST API endpoint with job manifest as parameter - Receive request from CockroachDB
- Source database query based on manifest (keyset pagination)
- Write query result to output stream in CSV format based on mapping in job manifest
- Repeat
3->4until no more rows
Example:
curl -X GET http://localhost:8090/sql2csv/form?table=products > sql2csv-products.json
curl -d "@sql2csv-products.json" -H "Content-Type:application/json" -X POST http://localhost:8090/sql2csv

- Submit job manifest to REST API
- Read CSV from local file system or cloud storage bucket
- Optional DDL for target database
- UPSERT data read in step 2 into target database
- Repeat
2->4until EOF
Example:
curl -X GET http://localhost:8090/flat2sql/form?table=products > flat2sql-products.json
curl -d "@flat2sql-products.json" -H "Content-Type:application/json" -X POST http://localhost:8090/flat2sql
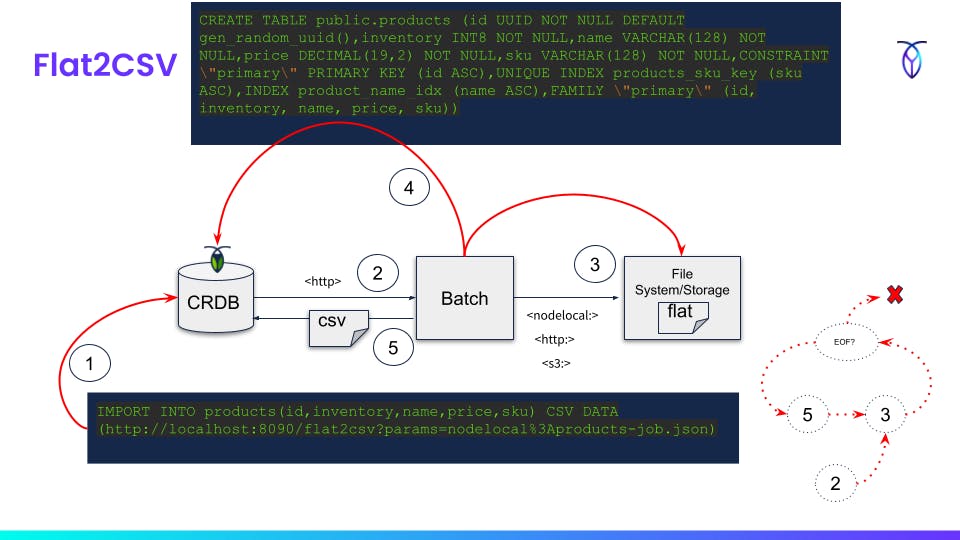
- Execute
IMPORT INTOcommand and point out REST API endpoint with job manifest as parameter - Receive request from CockroachDB
- Read fixed-width flat file from local file system or cloud storage bucket
- Optional DDL for target database
- Write query result to output stream in CSV format based on mapping in job manifest
- Repeat
3->5until no more rows
Example:
curl -X GET http://localhost:8090/flat2csv/form > flat2csv-products.json
curl -X GET http://localhost:8090/templates/products-schema.json > products-schema.json
curl -X GET http://localhost:8090/templates/products.txt > products.txt
curl -d "@flat2csv-products.json" -H "Content-Type:application/json" -X POST http://localhost:8090/flat2csv
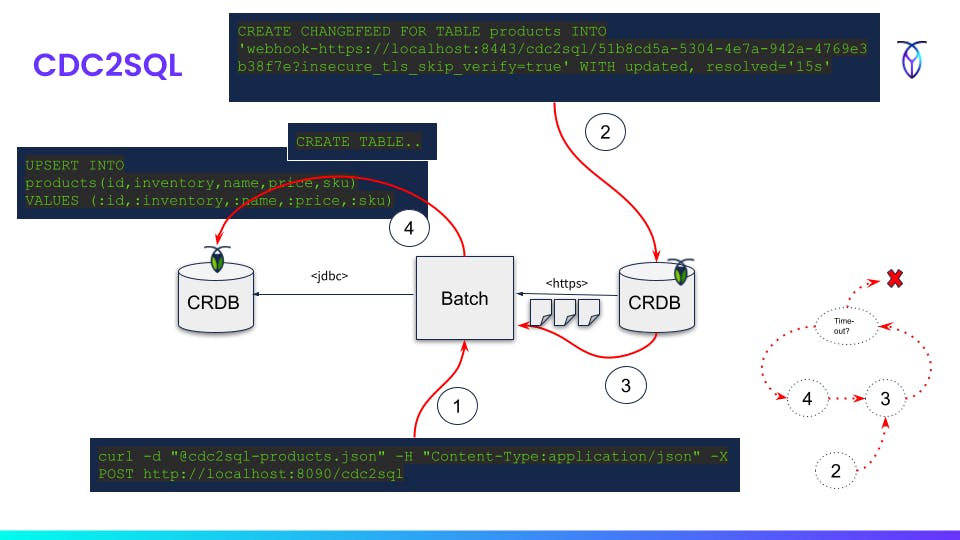
- Submit job manifest to REST API
- Create changefeed with webhook sink and use endpoint URI provided in step 1 response
- Receive changefeed payload events via HTTPS
- Optional DDL for target database
- UPSERT of each payload batch read in step 3 into target database
- Repeat
3->4until read timeout (5 min default)
Example:
curl -X GET http://localhost:8090/cdc2sql/form?table=products > cdc2sql-products.json
curl -d "@cdc2sql-products.json" -H "Content-Type:application/json" -X POST http://localhost:8090/cdc2sql
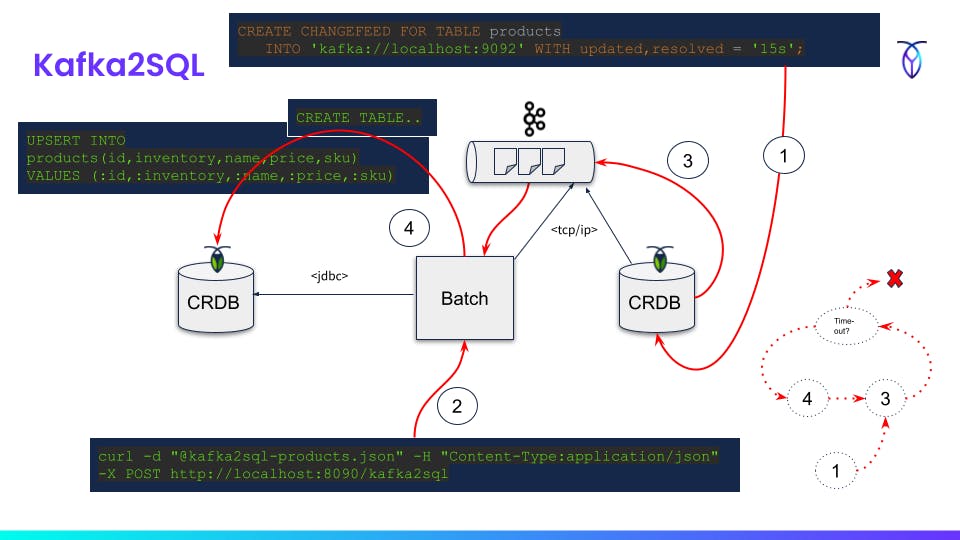
- Create changefeed with Kafka sink with use REST endpoint URI
- Submit job manifest to REST API (step 1 and 2 in either order)
- CockroachDB publishes CDC events to Kafka topic
- Receive CDC events from Kafka topic and UPSERT of each batch read into target database
- Repeat
3->4until read timeout (5 min default)
Example:
curl -X GET http://localhost:8090/kafka2sql/form?table=products > kafka2sql-products.json
curl -d "@kafka2sql-products.json" -H "Content-Type:application/json" -X POST http://localhost:8090/kafka2sql
Conclusion
Data migration tools for building data pipelines can take many shapes and forms. In this post, we looked at a fairly simple approach using micro-batching to ingest and extract data between different sources and sinks.