Bulk Update/Upserts with Spring Data JDBC
How to use bulk updates or upserts with Spring Data JDBC to improve write performance in CockroachDB

In a previous post Batch Statements with Spring Boot and Hibernate we used the PostgreSQL JDBC driver's reWriteBatchedInserts setting to batching INSERT statements for better performance (about 30%). This driver-level "rewrite" however only works for INSERTs which leads to the question: is it possible to do a similar thing for UPDATE or INSERT on CONFLICT, aka UPSERT statements? Let's find out.
Example Code
The code examples in this post are available on GitHub.
Introduction
Batch statements have a big performance impact since it reduces the number of roundtrips needed for the database. When creating records using JPA and Hibernate, we can use the Hibernate batch size setting to enable batch INSERTs. When using plain JDBC, we can use plain batch update statements. The PostgreSQL JDBC driver also requires setting reWriteBatchedInserts=true to translate batched INSERTs to multi-value inserts.
To perform bulk/batch UPDATEs or UPSERTs similarly, we can't rely on the JPA provider or JDBC driver to do any magic for us. Similar to INSERTs without rewrites, using the JDBC-prepared statement batch methods (addBatch/executeBatch) still means passing singleton statements over the wire.
Solution
One solution for UPDATEs is to use SQL values in bulk format and pass individual statements in batches of array values. The bulk array approach also works for INSERT on CONFLICT, aka UPSERTs.
Update Example
Rather than using JPA native queries, let's use JDBC through the Spring Data JDBC abstraction for simplicity. As always, it's important to use prepared statements with placeholders and parameter binding.
UPDATE products SET inventory=data_table.new_inventory, price=data_table.new_price
FROM
(select unnest(?) as id, unnest(?) as new_inventory, unnest(?) as new_price) as data_table
WHERE products.id=data_table.id
The ARRAY type works well in JDBC for parameter binding of List/Collection values. You just create one ordered list collection for each of the statement bind parameters populated with the values. If you have a very large collection, then you can either use pagination queries to narrow things or something like chunkedStream() below to split the stream into chunks matching the appropriate batch size.
Code example:
private static <T> Stream<List<T>> chunkedStream(Stream<T> stream, int chunkSize) {
AtomicInteger idx = new AtomicInteger();
return stream.collect(Collectors.groupingBy(x -> idx.getAndIncrement() / chunkSize))
.values().stream();
}
Let's put this into the context of a test method:
@Order(2)
@ParameterizedTest
@ValueSource(ints = {16, 32, 64, 128, 256, 512, 768, 1024})
public void whenUpdatingProductsUsingValues_thenObserveBatchUpdates(int batchSize) {
Assertions.assertFalse(TransactionSynchronizationManager.isActualTransactionActive(), "TX active");
logger.info("Finding all products..");
Stream<List<Product>> chunked = chunkedStream(productRepository.findAll().stream(), batchSize);
logger.info("Updating products in batches of {}", batchSize);
// This does send a single statement batch over the wire
chunked.forEach(chunk -> {
transactionTemplate.executeWithoutResult(transactionStatus -> {
int rows = jdbcTemplate.update(
"UPDATE products SET inventory=data_table.new_inventory, price=data_table.new_price "
+ "FROM "
+ "(select unnest(?) as id, unnest(?) as new_inventory, unnest(?) as new_price) as data_table "
+ "WHERE products.id=data_table.id",
ps -> {
List<Integer> qty = new ArrayList<>();
List<BigDecimal> price = new ArrayList<>();
List<UUID> ids = new ArrayList<>();
chunk.forEach(product -> {
qty.add(product.addInventoryQuantity(1));
price.add(product.getPrice().add(new BigDecimal("1.00")));
ids.add(product.getId());
});
ps.setArray(1, ps.getConnection()
.createArrayOf("UUID", ids.toArray()));
ps.setArray(2, ps.getConnection()
.createArrayOf("BIGINT", qty.toArray()));
ps.setArray(3, ps.getConnection()
.createArrayOf("DECIMAL", price.toArray()));
});
Assertions.assertEquals(chunk.size(), rows);
});
});
}
Upsert Example
Let's use the same concept for bulk UPSERTs:
INSERT INTO products (id,inventory,price,name,sku)
select unnest(?) as id,
unnest(?) as inventory,
unnest(?) as price,
unnest(?) as name,
unnest(?) as sku
ON CONFLICT (id) do nothing
Test code example:
@Order(4)
@ParameterizedTest
@ValueSource(ints = {16, 32, 64, 128, 256, 512, 768, 1024})
public void whenUpsertingProducts_thenObserveBulkUpdates(int batchSize) {
...
transactionTemplate.executeWithoutResult(transactionStatus -> {
int rows = jdbcTemplate.update(
"INSERT INTO products (id,inventory,price,name,sku) "
+ "select unnest(?) as id, "
+ " unnest(?) as inventory, "
+ " unnest(?) as price, "
+ " unnest(?) as name, "
+ " unnest(?) as sku "
+ "ON CONFLICT (id) do nothing",
ps -> {
List<Integer> qty = new ArrayList<>();
List<BigDecimal> price = new ArrayList<>();
List<UUID> ids = new ArrayList<>();
List<String> name = new ArrayList<>();
List<String> sku = new ArrayList<>();
products.forEach(product -> {
qty.add(product.getInventory());
price.add(product.getPrice());
ids.add(product.getId());
name.add(product.getName());
sku.add(product.getSku());
});
ps.setArray(1, ps.getConnection()
.createArrayOf("UUID", ids.toArray()));
ps.setArray(2, ps.getConnection()
.createArrayOf("BIGINT", qty.toArray()));
ps.setArray(3, ps.getConnection()
.createArrayOf("DECIMAL", price.toArray()));
ps.setArray(4, ps.getConnection()
.createArrayOf("VARCHAR", name.toArray()));
ps.setArray(5, ps.getConnection()
.createArrayOf("VARCHAR", sku.toArray()));
});
});
}
Performance
In a simple performance test updating 50,000 products, there's a 5x speed improvement of using bulk updates over normally prepared statement batch updates.
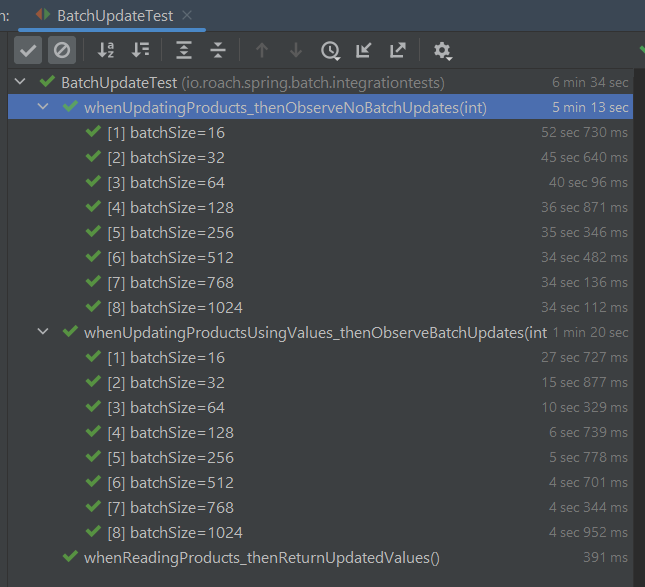
Conclusion
We looked at how to provide an equivalent for batch INSERTs with rewrites in the PostgreSQL JDBC driver for UPDATEs and UPSERTs. Using the bulk approach and array values can yield a 5x performance improvement.




