Data Domiciling using Super Regions in CockroachDB
Using super regions to implement data domiciling and region-level survival in CockroachDB

Introduction
Data domiciling is the art of controlling the placement of subsets of data in specific regions or locations. This is often required by privacy regulations like GDPR and The Wire Act in the US, where bet placements must not leave the state line where the bet was placed.
This presents an interesting technical challenge as far as databases are concerned: How do you still meet the database survival goals? For example, zone-level survival or even region-level survival when the data is not allowed to "leave" these boundaries?
You would like to avoid having to segment or shard your system in such a way that you end up with isolated islands deployed all across these different jurisdictions. That only adds operational complexity, risk and cost and also doesn't solve the survival problem.
What if you instead could use the database as one logical entity that stretches across all these locations while you can read, write and manage all data from any location? Without compromising on survival, consistency, transactional integrity, developer experience or data locality regulations, or having to redesign your apps or schemas?
This is complexity containment, where the challenges involved in providing these guarantees are moved from the business and application tier to the database itself, thereby offloading app developers to focus on domain-specific problems rather than data management problems.
In CockroachDB, this is achieved in two different ways depending on the survival goal defined for the database.
Data Domiciling with Zone Survival
Data domiciling in CockroachDB allows users to keep certain subsets of data in specific localities. For example US data only across nodes in the US, EU data across nodes in the EU and so forth for compliance and performance reasons. It’s transparent towards applications and implemented by controlling the placement of specific row or table data using regional tables with the REGIONAL BY ROW and REGIONAL BY TABLE clauses.
Replica placement constraints can be either through placement restrictions or super regions. For zone-level survival, placement restrictions is the approach. It tells the database to disable non-voting replicas and contain the placement of voting replicas to the specified home region (applied at the replication zone level).
For region survival, you will need to use super regions since it’s not possible to combine region survival with placement restrictions. Let's look at that in the next section.
For illustration, below is an example of using regional-by-row, with zone survival and placement restrictions:
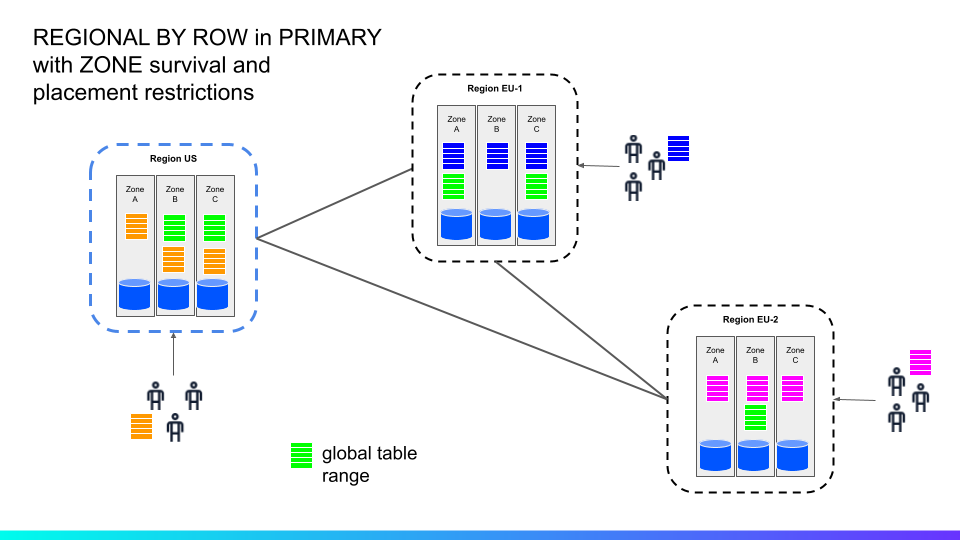
In this diagram, there is one regional-by-row table (yellow, blue and purple ranges) and one global table (green range). The RBR tables have domiciled ranges in each region, and the home region is defined at the row level. Non-voting replicas are disabled due to the use of placement restrictions, which is why you see three of them rather than five. Global tables are always excluded and unaffected by placement restrictions, so you can see them spread across all three regions.
Next, let’s look at a failure scenario in EU-1 where two nodes fail.

In the above diagram, forward progress is denied for the domiciled ranges in region EU-1 since there’s no majority available (2 of 3 offline). All other table ranges are available, including the ones for the global table.
This highlights the data domiciling challenge: How to provide region-level survival and data domiciling at the same time?
Data domiciling with zone survival is achieved with placement restrictions. A database can use PLACEMENT RESTRICTED to opt out of non-voting replicas, which can be placed outside of the regions indicated in zone configuration constraints.
In addition to data domiciling, PLACEMENT RESTRICTED can be used for the following:
Reduce the total amount of data in the cluster
Reduce the overhead of replicating data across a large number of regions
Note that global tables are not affected by PLACEMENT RESTRICTED and will still be placed in all database regions.
Data Domiciling with Region Survival
To implement data domiciling with region survival, you will need to use something called Super Regions. It was developed and introduced in CockroachDB 22.1 primarily for data domiciling requirements.
Super regions allow a user to define a set of regions in the database such that regional and regional-by-row tables located within the super region will have all of their replicas located within the super region.
In contrast to PLACEMENT RESTRICTED that disable non-voting replicas (with implications on remote region read performance), super regions make it so that all replicas (both voting and non-voting) are placed within the super region.
It means with super regions, you get to have both data domiciling and region survivability, and region-local latencies on reads and writes. The likelihood of a super-region having a full outage is significantly lower than a single region, but in case that would happen, only access to domiciled data would be refused.
Notice however that super regions rely on the underlying replication zone system, which was historically built for performance, not for domiciling. The replication system's top priority is to prevent the loss of data and it may override the zone configurations if necessary to ensure data durability.
In practical terms, this means that if there are not enough nodes in each region and super-region to satisfy the survival goal (replication factor), then it will prioritize avoiding data loss and place replicas outside of the domiciling constraints, which would be a violation of the placement constraints.
The ideal pattern for both performance, availability and compliance with super regions is therefore three nodes per region. This means you can lose a node in any region without needing to perform reads from a remote region and writes can reach a consensus agreement without cross-region coordination.
These additional guarantees come with a cost in terms of the number of nodes required. For two super regions, you effectively need 18 nodes in total.
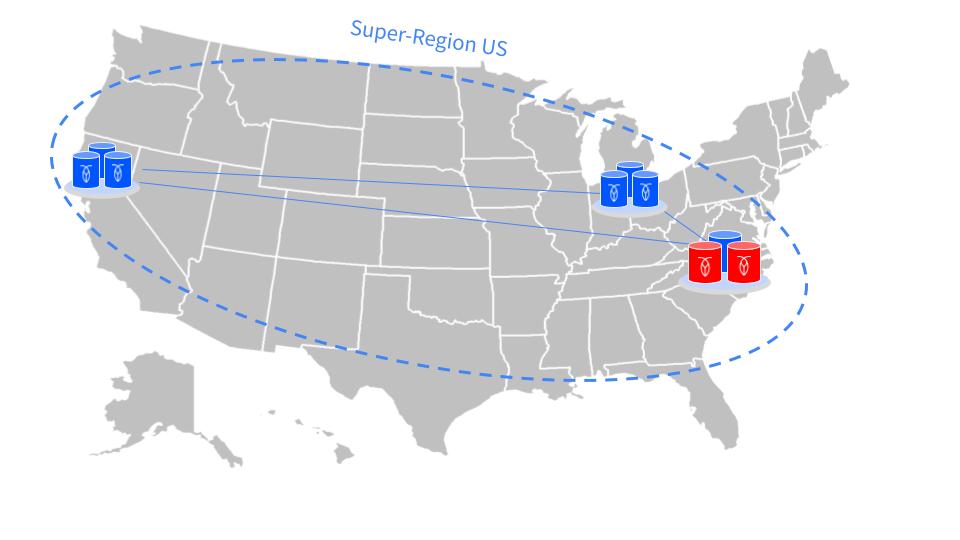
For example:
Super-region
UScontains:us-east-1 (a,b,c)us-east-2 (a,b,c)us-west-1 (a,b,c)
Super-region
EUcontains:eu-west-1 (a,b,c)eu-west-2 (a,b,c)eu-north-1 (a,b,c)
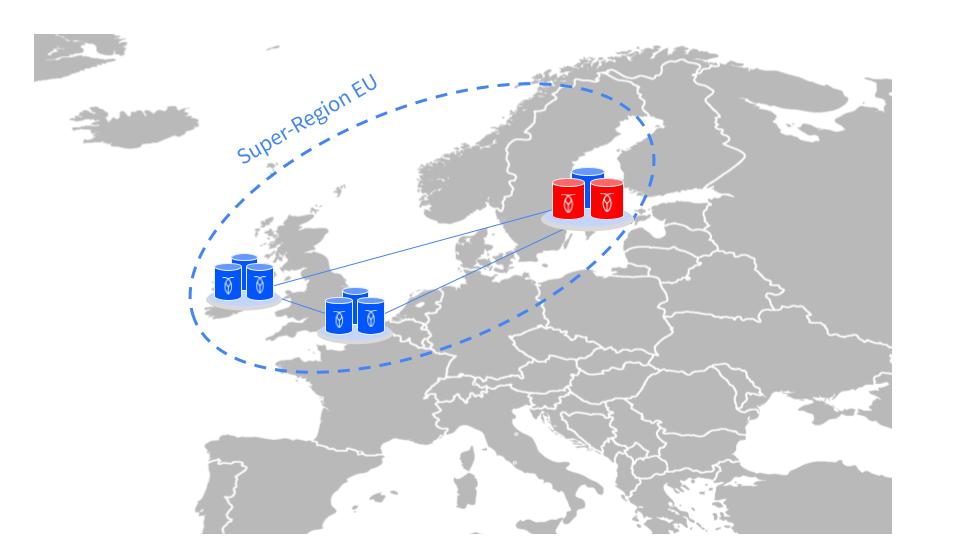
With 3 nodes in each region that sums up to 18 nodes. If each node is sized to 2vCPUs then the total vCPU count is 36, which isn't much more than a typical single-region CockroachDB cluster.
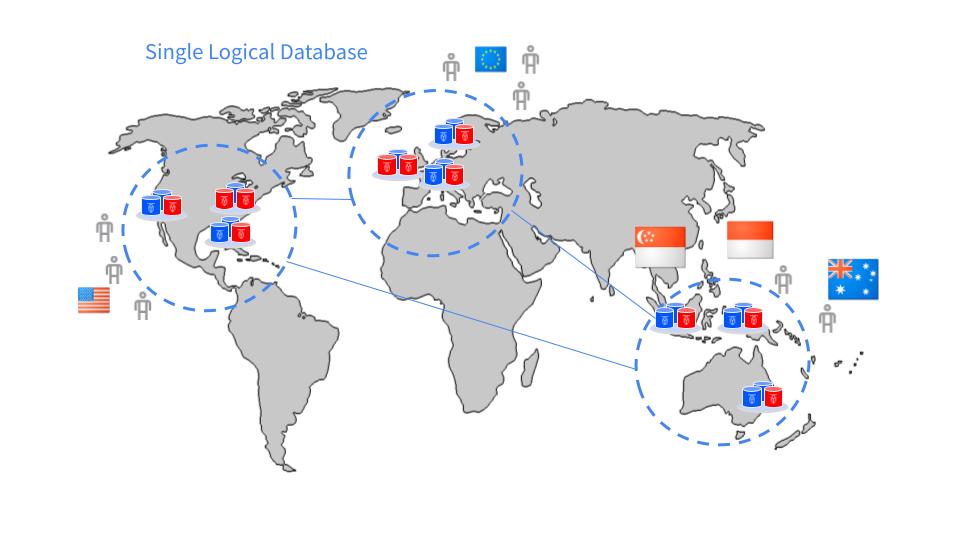
For every additional super-region, the ideal is adding 9 additional nodes in 3 regions, like in this example:
In this diagram, there are 3 super regions with domiciled data and it's still one single logical database.
Example
In this example, we will deploy a global cluster stretching the EU to the west and east coast of the US. We'll use 18 nodes in total, but run them all locally listening on different ports since it's just a demo. The example will not be exposed to the same type of cross-link latencies, but you could always add in fake network delays using different tooling.
This demo will focus mainly on the configuration and usability aspects of a setup like this.

Cluster Setup
To set this, we will use a simple script to start 18 nodes on a local machine.
#!/bin/bash
portbase=26258
httpportbase=8081
host=localhost
LOCALITY_ZONE=(
'region=eu-north-1,zone=eu-north-1a'
'region=eu-north-1,zone=eu-north-1b'
'region=eu-north-1,zone=eu-north-1c'
'region=eu-west-1,zone=eu-west-1a'
'region=eu-west-1,zone=eu-west-1b'
'region=eu-west-1,zone=eu-west-1c'
'region=eu-west-2,zone=eu-west-2a'
'region=eu-west-2,zone=eu-west-2b'
'region=eu-west-2,zone=eu-west-2c'
'region=us-east-1,zone=us-east-1a'
'region=us-east-1,zone=us-east-1b'
'region=us-east-1,zone=us-east-1c'
'region=us-east-2,zone=us-east-2a'
'region=us-east-2,zone=us-east-2b'
'region=us-east-2,zone=us-east-2c'
'region=us-west-1,zone=us-west-1a'
'region=us-west-1,zone=us-west-1b'
'region=us-west-1,zone=us-west-1c'
)
node=0;
for zone in "${LOCALITY_ZONE[@]}"
do
let node=($node+1)
let offset=${node}-1
let port=${portbase}+$offset
let httpport=${httpportbase}+$offset
let port1=${portbase}
let port2=${portbase}+1
let port3=${portbase}+2
join=${host}:${port1},${host}:${port2},${host}:${port3}
mempool="128MiB"
cockroach start \
--locality=${zone} \
--port=${port} \
--http-port=${httpport} \
--advertise-addr=${host}:${port} \
--join=${join} \
--insecure \
--store=datafiles/n${node} \
--cache=${mempool} \
--max-sql-memory=${mempool} \
--background
done
cockroach init --insecure --host=${host}:${portbase}
Next, we'll add the regions and configure the database for region-level survival.
create database test;
use test;
-- Add the 6 regions
alter database test primary region "eu-north-1";
alter database test add region "eu-west-1";
alter database test add region "eu-west-2";
alter database test add region "us-east-2";
alter database test add region "us-east-1";
alter database test add region "us-west-1";
show regions;
-- Add the super regions
SET enable_super_regions = 'on';
ALTER DATABASE test ADD SUPER REGION eu VALUES "eu-north-1","eu-west-1","eu-west-2";
ALTER DATABASE test ADD SUPER REGION us VALUES "us-west-1","us-east-2","us-east-1";
SHOW SUPER REGIONS FROM DATABASE test;
-- Enable region survival
ALTER DATABASE test SURVIVE REGION FAILURE;
Next, let's create two tables and add some sample data. The first postal_codes table is a global table and the second table users is using regional-by-row locality.
-- Add a GLOBAL table
create table postal_codes
(
id int primary key,
code string
);
ALTER TABLE postal_codes SET LOCALITY GLOBAL;
-- Insert some data
insert into postal_codes (id, code)
select unique_rowid() :: int,
md5(random()::text)
from generate_series(1, 100);
-- Add a regional-by-row table
CREATE TABLE users
(
id INT NOT NULL,
name STRING NULL,
postal_code STRING NULL,
PRIMARY KEY (id ASC)
);
-- Make it RBR
ALTER TABLE users SET LOCALITY REGIONAL BY ROW;
insert into users (id,name,postal_code,crdb_region)
select no,
gen_random_uuid()::string,
'123 45',
'eu-north-1'
from generate_series(1, 10) no;
insert into users (id,name,postal_code,crdb_region)
select no,
gen_random_uuid()::string,
'123 45',
'eu-west-1'
from generate_series(11, 20) no;
insert into users (id,name,postal_code,crdb_region)
select no,
gen_random_uuid()::string,
'123 45',
'eu-west-2'
from generate_series(21, 30) no;
insert into users (id,name,postal_code,crdb_region)
select no,
gen_random_uuid()::string,
'123 45',
'us-east-1'
from generate_series(31, 40) no;
insert into users (id,name,postal_code,crdb_region)
select no,
gen_random_uuid()::string,
'123 45',
'us-east-2'
from generate_series(41, 50) no;
insert into users (id,name,postal_code,crdb_region)
select no,
gen_random_uuid()::string,
'123 45',
'us-west-1'
from generate_series(51, 60) no;
select *,crdb_region from users;
You may notice above that use used explicit region values when inserting into the users table. This isn't required but we do it here so we can see how the replica placement works.
Finally, let's run through a series of tests to observe the data domiciling and also run a compliance report query.
--- Observe
SHOW CREATE TABLE postal_codes;
SHOW PARTITIONS FROM TABLE postal_codes;
SHOW RANGES FROM TABLE postal_codes;
SHOW CREATE TABLE users;
SHOW PARTITIONS FROM TABLE users;
SHOW RANGES FROM TABLE users;
show zone configuration for table users;
-- Look for constraint compliance (notice this doesnt tell if the row exists, only where it would be stored)
SHOW RANGE FROM TABLE users FOR ROW ('eu-north-1',1);
SHOW RANGE FROM TABLE users FOR ROW ('eu-west-1',1);
SHOW RANGE FROM TABLE users FOR ROW ('us-east-1',1);
SHOW RANGE FROM TABLE users FOR ROW ('us-east-2',1);
SHOW RANGE FROM TABLE users FOR ROW ('us-west-1',1);
SELECT * FROM system.replication_constraint_stats WHERE violating_ranges > 0;
WITH partition_violations AS (SELECT * FROM system.replication_constraint_stats WHERE violating_ranges > 0),
report AS (SELECT crdb_internal.zones.zone_id,
crdb_internal.zones.subzone_id,
target,
database_name,
table_name,
index_name,
partition_violations.type,
partition_violations.config,
partition_violations.violation_start,
partition_violations.violating_ranges
FROM crdb_internal.zones,
partition_violations
WHERE crdb_internal.zones.zone_id = partition_violations.zone_id)
SELECT *
FROM report;
Conclusion
Multi-region CockroachDB clusters must contain at least 3 regions to ensure that data replicated across regions can survive the loss of one region.
Data domiciling in multi-region configurations allow users to keep certain subsets of data in specific localities for privacy regulations and performance reasons.
For zone-level survival, this is achieved by using replica placement restrictions. For region-level survival, this is achieved by using super regions.
Super regions must contain at least 3 subregions to ensure that data replicated across the subregions can survive the loss of one region. This leads to a higher total node count for a cluster (18 minimum) but in return, you can get both region-level survival and data domiciling requirements satisfied.




