Exploring Fault Tolerance in CockroachDB
"Trust is good, control is better"

CockroachDB Fault Tolerance
As the name reveals, CockroachDB is designed to survive all sorts of failure scenarios. From individual nodes crashing to asymmetric network partitions, zone and region level failures. Caused perhaps by non-mundane events, like a melted power supply, flooding, fire, a wider power outage or perhaps sharks taking a bite off the fiber link:

Make no mistake, these incidents do happen like for this rather business critical rock island in the Mediterranean a few years back:
Database survival can be defined as the ability to make forward progress on both reads and writes during a service disruption. If a client can reach a node with a request, it should either allow or refuse it in respect to liveness and safety. A safety property asserts that nothing bad happens during execution. A liveness property asserts that something good eventually happens. Another way of putting it: liveness means that a specific event must occur, while safety means that an unintended event must not occur. This is essential for things like failure detection and consensus algorithms.
To use CAP terminology, CockroachDB is CAP-consistent, which means it can be partially unavailable in the event of a network partition in order to not compromise consistency. Partially unavailable means that some requests may succeed while others may not, depending on factors like which side of a network partition the client and node sits on, leaseholder status for the range that a key sorts into, etc. Keep in mind that the client (application) is also an actor in any distributed system.
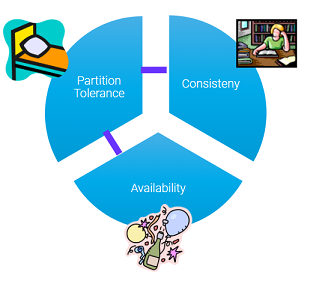
^^ CAP simplified: A system is either (C)onsistent or (A)vailable when (P)artitioned
But how can you actually demonstrate that this works? That a node does not return a non-authoritative read when its not allowed to, or worse, a dirty or phantom read or allowing a write to succeed which later disappears?
It's like Lenin said: "Trust is good, control is better", amongst a few other things..

There are many ways to achieve this, as always. Either by running a simulation of some kind, or using an actual system under load while monitoring invariants or a chaos type testing scenario like the Jepsen framework. The latter option requires more upfront planning and tooling, but its a good way to find edge cases and gain confidence that there's are no gaps between expected and actual outcomes under chaos.
The rest of this article will narrow things down to a much simpler approach (yet more limited) by focusing on verifying expected vs actual outcome at the level of individual read and write operations when nodes are taken down violently. No special tooling is needed besides the CLI and ssh.
Introduction to CockroachDB Fault Tolerance
For further insights to CockroachDB HA properties and a glossary of the terms used in the article, see:
- https://www.cockroachlabs.com/docs/stable/multi-active-availability.html
- https://www.cockroachlabs.com/docs/stable/architecture/glossary.html
CockroachDB stores user data in 512 MiB sized ranges that are replicated three times (by default) across failure domains for maximum diversification. A failure domain can be a machine, rack, datacenter, an availability zone, region or even a cloud provider. For the database to function properly, a majority of replicas must be available at all times (⅔).
The number of failures that can be tolerated in CockroachDB is equal to (replication factor - 1)/2. For example, with 3x replication (the default), one failure can be tolerated; with 5x replication, two failures, and so on. The replication factor can be controlled at cluster, database, table and index level using replication zones. The replication factor is automatically adjusted based on defined database survival goals in a multi-region deployment (zone or region survival).
It is recommended to run CockroachDB across a minimum of three failure domains for optimal resilience. To guarantee a zero RPO (no data loss) and near-zero RTO (<10s), it is imperative that these failure domains be sufficiently isolated from each other such that the risk of simultaneously losing a majority of them is extremely rare.
Running a CockroachDB cluster across two failure domains is therefore considered a CockroachDB anti-pattern because the loss of a single failure domain could lead to unavailability. Avoid the number 2 and you are in a better spot, pretty much.
Test Setup
Prerequisites
The test scenarios expects a pre-provisioned CockroachDB cluster with the following outline:
- 6 node cluster, single region, 2 nodes per zone
- Using default replication factor of 3
- One database with 2 tables, populate with some data
- Self-hosted for the ability to kill nodes
- v22.1 or later
Example localities, for illustration:
--locality=region=eu-west-1,datacenter=eu-west-1a
--locality=region=eu-west-1,datacenter=eu-west-1b
--locality=region=eu-west-1,datacenter=eu-west-1c
--locality=region=eu-west-1,datacenter=eu-west-1a
--locality=region=eu-west-1,datacenter=eu-west-1b
--locality=region=eu-west-1,datacenter=eu-west-1c
Schema
Table schema with two tables and some data used in the scenarios:
create table users
(
id int not null default unique_rowid(),
city string not null,
first_name string not null,
last_name string not null,
address string not null,
primary key (id asc)
);
create index users_last_name_index on users (city, last_name);
insert into users (id,city,first_name,last_name,address)
select n,
'london',
md5(random()::text),
md5(random()::text),
md5(random()::text)
from generate_series(1,10000) n;
Test Scenarios
The test scenarios have different assertions, principles in use and steps for validation.
Scenario A - Reads during Failure
Assertion
A read for a key must not complete when the leaseholder for that range is unavailable.
Principles
- Only the leaseholder replica is allowed to service reads and writes for a range unless it's a follower read (opt-in feature), in which case follower replicas can serve potentially stale reads.
- The leaseholder can service reads until it's epoch expires due to failure to update its liveness record stored in a system range (these are replicated 5 times by default).
- A follower node or gateway node that cannot reach the leaseholder for a range will not complete.
Resources
- https://www.cockroachlabs.com/docs/stable/architecture/reads-and-writes-overview
- https://www.cockroachlabs.com/docs/stable/architecture/replication-layer#epoch-based-leases-table-data
Steps to verify
1) Take note of the range distribution and leaseholder for the first key in users table, designated K1
SHOW RANGE FROM TABLE users FOR ROW (1);
start_key | end_key | range_id | lease_holder | lease_holder_locality | replicas | replica_localities
------------+---------+----------+--------------+----------------------------------+----------+-------------------------------------------------------------------------------------------------------------
NULL | NULL | 45 | 1 | region=eu-west-1,zone=eu-west-1a | {1,5,6} | {"region=eu-west-1,zone=eu-west-1a","region=eu-west-1,zone=eu-west-1c","region=eu-west-1,zone=eu-west-1b"}
(1 row)
The SHOW RANGE FROM TABLE statement asks the database where it would store the row key. In this case across replicas 1, 5 and 6 with 1 being the leaseholder. Keep in mind this does not tell you if the row actually exist. For that you can use a point lookup in combination.
2) Kill two nodes holding K1 replicas, one being the current leaseholder. In the above output, lets pick 1 and 5:
(ssh to node 1)
killall -9 cockroach
(ssh to node 5)
killall -9 cockroach
3) Connect with a SQL client to any other node that holds the last reachable replica for K1 and execute
a point lookup. In the above example, its node 6:
(ssh to node 6)
SELECT * from users where id=1;
(blocks until timeout)
If you wait too long you may also get:
ERROR: replica unavailable: (n6,s6):2 unable to serve request to r45:/Table/106{-/2} [(n1,s1):1, (n6,s6):2, (n5,s5):5, next=6, gen=17]: lost quorum (down: (n1,s1):1,(n5,s5):5); closed timestamp ...[truncated]
4) Restart the 2 failed nodes
5) Observe that the blocked or failing read in step 3 now completes
Scenario B - Writes during Failure
Assertion
A write to a key must not complete if the leaseholder for that range is unavailable.
Principles
- A transaction can only commit if a majority of range replicas are in agreement (raft consensus).
- The range leaseholder, aka raft group leader ensures this.
Resources
- https://www.cockroachlabs.com/docs/stable/architecture/life-of-a-distributed-transaction.html
- https://www.cockroachlabs.com/blog/parallel-commits/
Steps to verify
1) Take note of the range distribution and leaseholder for the first key in users table, designated K1 (same as in previous scenario)
SHOW RANGE FROM TABLE users FOR ROW (1);
start_key | end_key | range_id | lease_holder | lease_holder_locality | replicas | replica_localities
------------+---------+----------+--------------+----------------------------------+----------+-------------------------------------------------------------------------------------------------------------
NULL | NULL | 45 | 1 | region=eu-west-1,zone=eu-west-1a | {1,5,6} | {"region=eu-west-1,zone=eu-west-1a","region=eu-west-1,zone=eu-west-1c","region=eu-west-1,zone=eu-west-1b"}
(1 row)
2) Kill two nodes holding K1 replicas, one being the current leaseholder. In the above output, lets pick 1 and 6:
(ssh to node 1)
killall -9 cockroach
(ssh to node 6)
killall -9 cockroach
3) Connect to any node that does not hold a replica for K1, lets pick 2:
(ssh to node 2)
SELECT * from users where id=1;
(blocks until timeout)
4) Connect to any node in yet another session and update K1:
(ssh to node 3)
UPDATE users SET last_name = 'xxx' where id=1;
(blocks until timeout)
6) Restart the two nodes
7) Observe that both blocked/failing operations (3 and 4) complete
Note: If the UPDATE in step 4 is done in an explicit transaction and the client then terminates while waiting, the update will not become visible (aborted transaction).
Conclusion
This article touched on the surface on CockroachDBs survival properties. We used a simplicity yet limited approach to verify read and write behavior under failure. As a next step and follow-up, we'll look at the HA characteristics in a global, multi-region deployment. That's typically when things get really interesting.




