Keeping different copies of state in sync with CDC and the Outbox pattern in CockroachDB
Implementing the transactional outbox pattern in CockroachDB using CDC and TTLs

Background
Distributed architectures are common nature these days in most business domains. Driven by the urge to decompose monoliths into more independent microservices or to adopt event-driven principles when building shiny new things. The goal is to enhance decoupling, independent evolution, scalability and fault-tolerance and in the end cost of change.
Unfortunately, there's no free lunch and distributed architecture styles come with a different set of challenges. One of these challenges is in focus for this post - how to keep different copies of state in sync.
What are different copies of state and why is that a challenge? Let's find out.
Problem
Let's focus on a typical request-response-based interaction model where each microservice has its bounded context with an API to front clients and an isolated database (aka state) and some stateless business processing in between.
One side-effect of having many (potentially hundreds) independent services that don't share the same database is conversational chatty: ness over the network. That not only impacts performance but also increases service coupling and reduces availability when synchronous channels are used like HTTP APIs.
For example, you have a customer service that represents the technical authority for your domain concept of a "customer". If you need to register a new customer, that request must go to the customer service for validation. If a customer changes address, that change must be done through the customer service, etc.
When a registered customer later opts into a loyalty program, however, that typically doesn't belong in the customer service domain but somewhere else, like in the loyalty domain. The loyalty service may also need to have a basic understanding of what a customer is beyond just an ID or token without necessarily representing the authority to do any changes. Whenever the loyalty system runs its routines, it may need to interact with customer service unless it has a local, shallow copy of the customer's details.
The same goes for the more high-volume use case. Assume you have a strict regulatory requirement to check a customer's spending limit (or blocks) before accepting anything with money wagering. Like placing an online bet or joining a poker ring tournament. That spending limit happens to sit next to the customer details in the customer service. Again, unless you have a shallow copy of the customer details with the spending limit locally the customer service must be consulted each time through a synchronous API call.
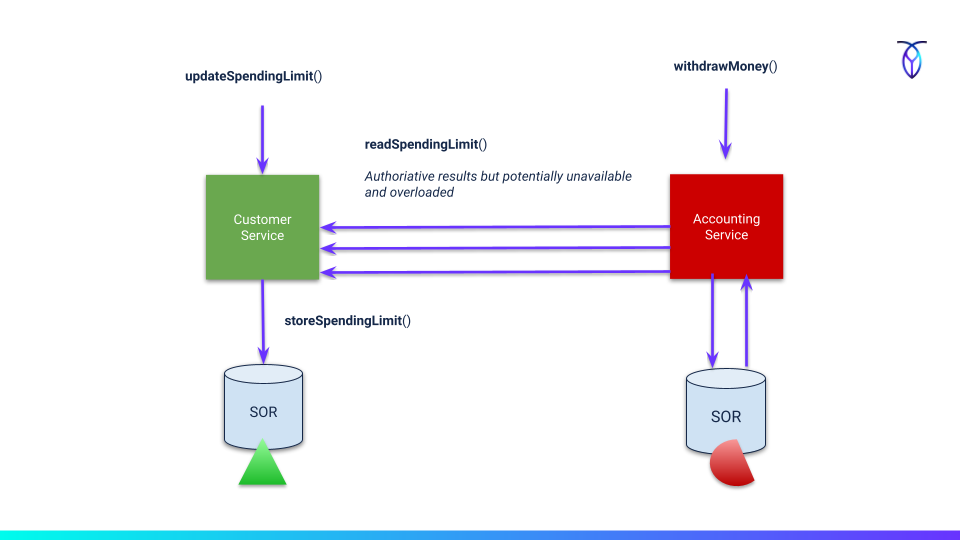
(Fig 1) Chatty: ness against service hotspots
One way to work around this side-effect is by a pattern called data redundancy.
In the microservice architecture style, there is only one technical authority for any piece of domain data stored in an isolated database that we call the system of record. This database is not exposed or shared outside of the service boundary. The interaction with other services instead goes through synchronous calls or events carrying pieces of that data. Then you can have any number of copies of that data, potentially in different shapes and forms as materialized views downstream in other services. These views may be slightly stale but that's acceptable since one of the characteristics of microservices is eventual consistency and coordination without transactions across domain boundaries.
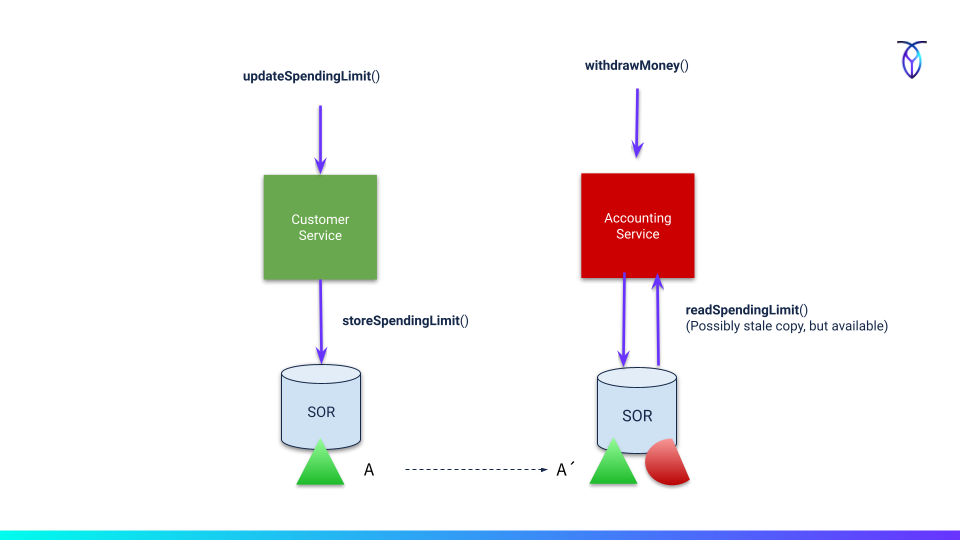
(Fig 2) Data redundancy
To illustrate this further, one service can have derived materialized views of data from other services that are frequently read from, but never written to since there's no authority to change. Changes must instead ripple through the system of record.
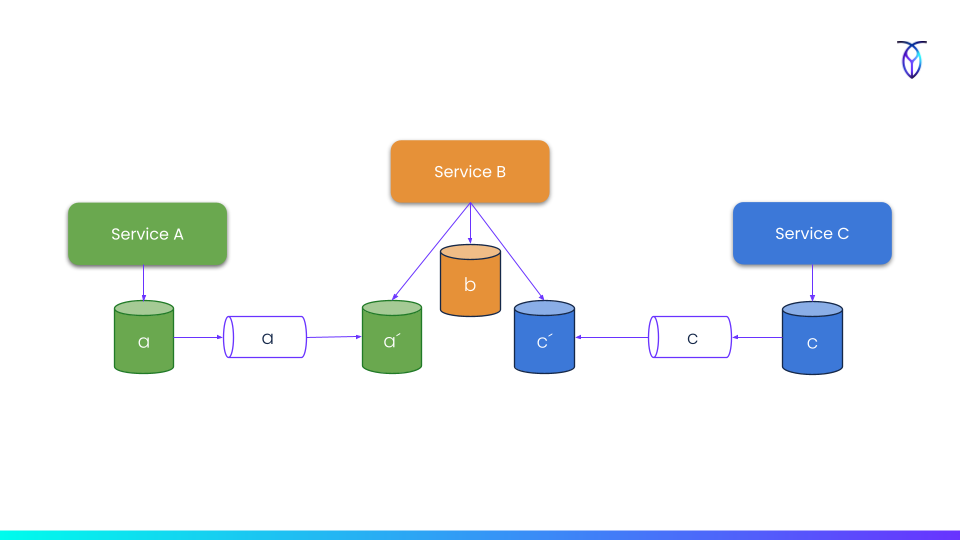
(Fig 3) Data redundancy
Now, with all these copies of state loitering around, how do you keep them in sync with the authoritative source? It seems quite similar to the cache invalidation problem which next to naming things is one of the most challenging problems in software development.
Going back to the spending limit use case, we could publish a domain event alongside writing to the database. When the subscriber receives that event, it updates its local copy by making an API call to the origin (for example) if the event itself doesn't carry that information.
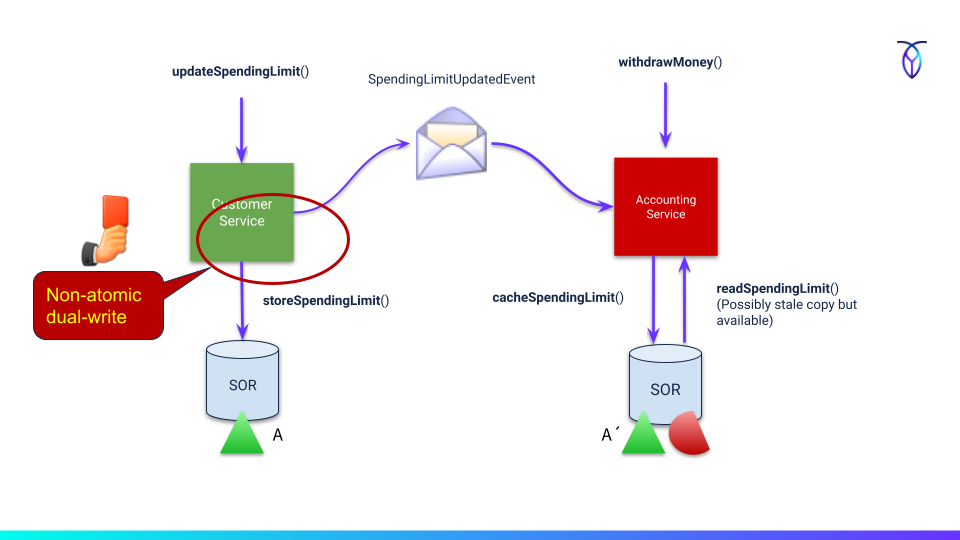
*(Fig 4) Updating the view *
The problem here is that we are attempting to commit changes to two independent systems at the same time without any transactional coordination. This is the dual-write problem which, in reality, is more of a risk and potential business liability than an actual problem that appears every time.
Sometimes the risk could be worth taking also, which is what the late-commit 1PC pattern is used for. Doing all the business validations up-front before commit time so the only real risk of failure is likely to be infrastructure-related (networking, servers or downstream components). For certain domains like financial services that may still not be good enough. Given the possibility of network partitions and node crashes, it is still a risk that you'd want to mitigate using transactions of some form.
When dual-writes is considered a bad practice in general, we of course want to find a reasonable solution for it. Let's focus on the transactional outbox solution.
Outbox Solution
The idea is to have an "outbox" table (like with e-mails) that you write the domain event to as part of the local database transaction. That way, if there is an issue with the database and there's a transaction rollback, the outbox event is not made visible either.
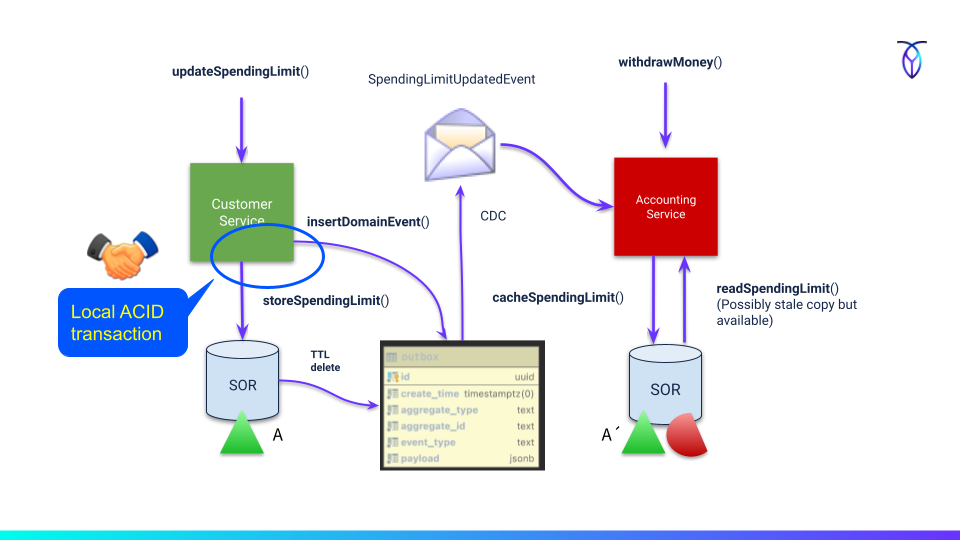
*(Fig 5) Avoiding dual-writes by outbox table *
The next thing is that you need to have the events in the outbox published and also eventually cleared away to save space. You could use a polling publisher that frequently polls the outbox table and publishes events to the message bus. Alternatively, you can use change data capture (CDC) to publish the event instantly after a transaction commits. The event is already stored in "domain event" format and ready to go.
Lastly, to remove expired events from the outbox you could either have a periodic cleanup cron job or leverage the database TTL feature if there is one available (recently added to CockroachDB).
Downsides
It may seem like having duplicate copies of state is a downside, but with microservices it kind of makes sense. Duplicating data reduces dependencies and interaction over the network, and also increases the decoupling between services and strengthens their roles as a single authority.
The Outbox Pattern looks easy enough on paper, but keep in mind that most databases are not designed to handle high-frequency message bus type-of-workloads at an "unlimited" scale. Depending on the database architecture, it does add some overhead in terms of storage space, LSM compactions, MVCC garbage collection and CPU cycles to keep the events rolling. Distributed databases today are designed for more complicated use cases than pushing events around.
Outbox still provides quite an elegant and robust mechanism that can go quite far if not over-used for every possible thing that a dedicated event bus/message broker is more suitable for. You still need to use some form of eventing/messaging component anyway, either a pub/sub system or a commit log service like Kafka.
Outbox Alternatives
To safely overcome the dual-write problem, using the transactional outbox pattern is one option. Two-phase commits protocols like XA are another, but it's less common and not widely supported in databases or messaging/eventing systems.
Self-subscribing to events and re-publishing them is a third (bottom left corner):
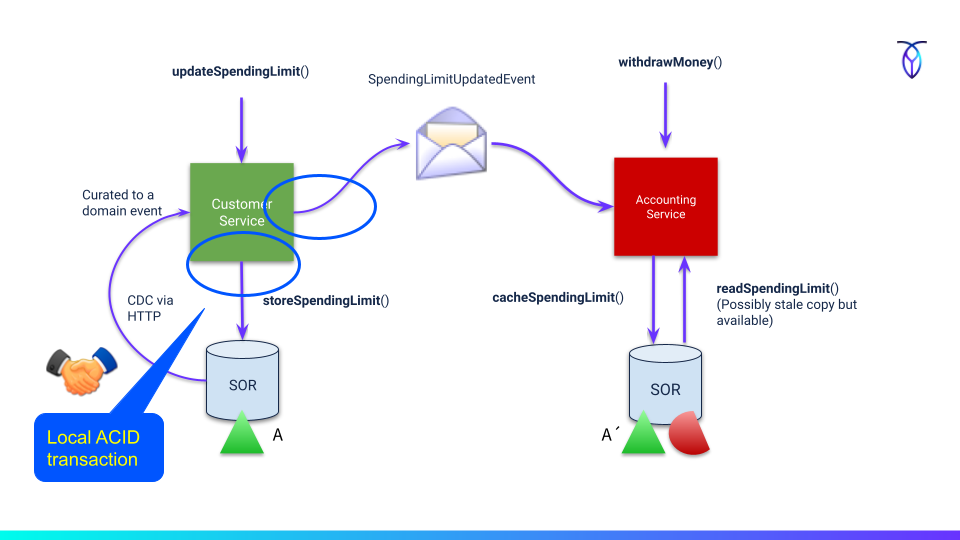
Either by just writing the event/request in a local transaction and then receiving it back as a CDC event and again writing it back in a normalized structure.
The CDC event could (if curated to a domain event) also be published to other subscribers interested in that business event.
Going even further and we start entering the realm of event sourcing where the events themselves are the source of truth and the database may just store materialized views. There's no free lunch with that either though.
Guarantees
When using the outbox pattern the best guarantee you will get is at-least-once delivery of the events. There's always a chance of receiving the same event multiple times no matter what system is used (Kafka, NATS, Pub/Sub, etc) and you need to be ready to handle it application side with deduplication.
You can't get exactly-once delivery in any formal sense as an end-to-end guarantee across systems where events are neither lost nor duplicated and delivered exactly once to a consumer. No such thing exists. What you can get, however, is the means for exactly-once processing semantics as a desired outcome where you don't end up causing multiple side effects due to double processing.
Having the event-bus system do de-duplication and transactions towards producers and consumers (like in Kafka) is a closed system guarantee. You still need to make processing with side-effects (like writing to a database) at the consumer side idempotent on your own or use 2PC distributed transactions. When using Kafka for example, you could store the consumer offset in your system of record (like the database) for later de-duplication by resuming from the last acknowledged offset.
Example Solution
Enough chit-chat, let's kick the tires with a simple demonstration. It just so happens that we are again tasked with building an online bank. We are going to implement it using Spring Boot and CockroachDB and then leverage CDC and TTLs for the outbox part.
The code examples are available on Github.
Assume the following schema:
create table t_account
(
id int not null default unique_rowid(),
balance float not null,
creation_time timestamptz not null default clock_timestamp(),
primary key (id)
);
create table t_transaction
(
id int not null default unique_rowid(),
account_id int not null,
amount float not null,
transaction_type string not null default 'generic',
transaction_status string not null default 'pending',
creation_time timestamptz not null default clock_timestamp(),
primary key (id)
);
alter table if exists t_transaction
add constraint fk_transaction_ref_account
foreign key (account_id)
references t_account (id);
create index fk_account_id_ref_account_idx on t_transaction (account_id);
We have accounts and monetary transactions performed against those accounts. When creating a monetary transaction we also want to publish that as a domain event in the form of an aggregate:
{
"id" : 777000849956503553,
"account" : {
"id" : 777000849212538881,
"balance" : 0.8667041474557778,
"creationTime" : "2022-07-07T13:10:41.190359"
},
"amount" : 0.9017766053267938,
"transactionType" : "debit",
"transactionStatus" : "pending"
}
Rather than INSERT: ing the transaction in one database transaction and then publishing the domain aggregate (or the other way around) as a dual-write, we use the outbox pattern.
Let's first create a table for storing these events:
create table t_outbox
(
id uuid not null default gen_random_uuid(),
create_time timestamptz not null default clock_timestamp(),
aggregate_type string not null,
aggregate_id string null,
event_type string not null,
payload jsonb not null,
primary key (id)
);
The columns can be anything that identifies the events and semantics needed to process them, like an event_type that is later accompanied by an Avro schema. In this case, we are using plain JSON.
Now, all we need to do is INSERT both the transaction and the domain aggregate event to the outbox table in a single local database transaction:
Name:, Connection:9, Time:10, Success:True
Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["insert into t_transaction (account_id, amount, transaction_status, transaction_type) values (?, ?, ?, ?)"]
Params:[(777000849212538881,0.9017766053267938,pending,debit)]
Notice the same Connection id (9):
Name:, Connection:9, Time:8, Success:True
Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["INSERT INTO t_outbox (aggregate_type,aggregate_id,event_type,payload) VALUES (?,?,?,?)"]
Params:[(transaction,777000849956503553,TransactionCreatedEvent,{
"id" : 777000849956503553,
"account" : {
"id" : 777000849212538881,
"balance" : 0.8667041474557778,
"creationTime" : "2022-07-07T13:10:41.190359"
},
"amount" : 0.9017766053267938,
"transactionType" : "debit",
"transactionStatus" : "pending"
})]
To avoid having to clean up the events manually, we can leverage CockroachDB's new TTL feature:
ALTER TABLE t_outbox SET (ttl_expire_after = '5 minutes', ttl_job_cron = '*/5 * * * *', ttl_select_batch_size = 256);
This will create an internal job that runs every 5 minutes and deletes all expired rows in batches.
Last but not least, we need to create a change feed for the outbox events:
CREATE CHANGEFEED FOR TABLE t_outbox
INTO 'webhook-https://localhost:8443/webhook?insecure_tls_skip_verify=true'
WITH updated, resolved='15s',
webhook_sink_config='{"Flush": {"Messages": 5, "Frequency": "1s"}, "Retry": {"Max": "inf"}}';
In the above case, CockroachDB is publishing events to an HTTP endpoint (webhook sink) at the specific URI. We could also use Kafka, Google Cloud Pub/Sub or a cloud storage sink:
CREATE CHANGEFEED FOR TABLE t_outbox INTO 'kafka://localhost:9092' with updated, resolved='15s';
Code
The business service is very basic and we are just writing the monetary transaction entity to the database:
@Service
public class DefaultTransactionService implements TransactionService {
@Autowired
private TransactionRepository transactionRepository;
@Override
@Transactional(propagation = Propagation.REQUIRES_NEW)
public TransactionEntity createTransaction(TransactionEntity entity) {
Assert.isTrue(TransactionSynchronizationManager.isActualTransactionActive(), "Transaction expected!");
transactionRepository.save(entity);
return entity;
}
}
The outbox event is created using AOP to make that concern non-intrusive which may come in handy when we start adding more aggregates.
@Aspect
@Component
@Order(Ordered.LOWEST_PRECEDENCE - 1) // Make sure it's ordered after TX advisor (by a higher value)
public class OutboxAspect {
protected final Logger logger = LoggerFactory.getLogger(getClass());
private final ObjectMapper mapper = new ObjectMapper()
.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS)
.disable(SerializationFeature.FAIL_ON_EMPTY_BEANS)
.enable(DeserializationFeature.ACCEPT_EMPTY_STRING_AS_NULL_OBJECT)
.setSerializationInclusion(JsonInclude.Include.NON_NULL);
@Autowired
private DataSource dataSource;
private JdbcTemplate jdbcTemplate;
@PostConstruct
public void init() {
logger.info("Bootstrapping outbox aspect");
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
@AfterReturning(pointcut = "execution(* io.roach.spring.outbox.domain.DefaultTransactionService.createTransaction(..))", returning = "transactionEntity")
public void doAfterCreateTransactions(TransactionEntity transactionEntity) {
if (!TransactionSynchronizationManager.isActualTransactionActive()) {
throw new IllegalStateException("No transaction context");
}
Assert.isTrue(!transactionEntity.isNew(), "Expected persistent entity but got transient");
try {
String payload;
if (logger.isTraceEnabled()) {
payload = mapper.writer()
.withDefaultPrettyPrinter()
.writeValueAsString(transactionEntity);
logger.trace("Writing payload to outbox: {}", payload);
} else {
payload = mapper.writer()
.writeValueAsString(transactionEntity);
}
jdbcTemplate.update(
"INSERT INTO t_outbox (aggregate_type,aggregate_id,event_type,payload) VALUES (?,?,?,?)",
ps -> {
ps.setString(1, "transaction");
ps.setString(2, transactionEntity.getId().toString());
ps.setString(3, "TransactionCreatedEvent");
ps.setObject(4, payload);
});
} catch (JsonProcessingException e) {
throw new IllegalStateException("Error serializing outbox JSON payload", e);
}
}
}
We are using an @AfterReturning advice to hook in the outbox part after the completion of the business method but before the transaction commits. The assertions are there to ensure it's not separate transactions which would other invalidate the whole concept.
Conclusion
Since the rise of distributed architectures across many business domains, there's been an increased usage of the classic Outbox Pattern in favor of using XA and a two-phase commit protocol to ensure transactional safety and robustness. It provides strong transactional integrity and scales fairly well. We demonstrated using CDC rather than a polling publisher to get the events published and using TTLs to clean up events automatically.
References
https://microservices.io/patterns/data/transactional-outbox.html
https://martinfowler.com/articles/patterns-of-distributed-systems/two-phase-commit.html




