JPA Best Practices - Optimizing JPA Mappings
JPA and CockroachDB - Part 3

Introduction
This article is part three of a series of data access best practices when using JPA and CockroachDB. The goal is to help reduce the impact of workload contention and to optimize performance. Although most of the principles are fairly framework and database agnostic, it’s mainly targeting the following technology stack:
JPA 2.x and Hibernate
CockroachDB v22+
Spring Boot
Spring Data JPA
Spring AOP with AspectJ
Example Code
The code examples are available on Github.
Chapter 3: Optimizing JPA Mappings
JPA is a set of standard JakartaEE (aka JavaEE aka J2EE) interfaces, while Hibernate is a JPA vendor implementation that also provides a non-standard interface.
Object-relational-mapping frameworks such as Hibernate offer a lot of value for rich domain/entity models, but also a lot of hidden complexity. This complexity is partly due to the impedance mismatch between the relational world and the object-oriented world but also due to the very rich feature set.
While ORMs often make sense in improving development efficiency, it’s not always visible what goes on under the hood and that can result in negative performance characteristics. Mainly in the form of inefficient SQL queries.
3.1 How to use JPA and Hibernate for best performance
Problem
You want to know how to optimize JPA/Hibernate for the best performance.
Solution
Let’s begin with database reads. The key to high read performance is to avoid extremes, in terms of both under-fetching and over-fetching data. This can only be done through careful analysis of the data access patterns and underlying schema. One starting point is to adopt lazy-loading everywhere and then eager join fetch as an exception to reduce the N+1 effect.
For example, if you have Order, OrderItem and Product entities linked together to form an aggregate (like a purchase order), and know you will always read the full domain aggregate, then a join fetch strategy could be appropriate. Otherwise, JPA will first fetch the order, then do a lazy-initialized query for the items and then again for products attached to the items. A join fetch could be more efficient in that case, or a sub-select fetch strategy depending on the mapping. When domain aggregates are fairly small and retrieved as a whole, then it’s a good case argument for join fetching. Otherwise, just fall back to lazy fetching.
For best write performance, using batch updates and multi-value INSERTs will make a big difference. There are a few pre-conditions for batching to be enabled, and it’s disabled by default. One is you need to set specific configuration parameters and also avoid the IDENTITY primary id generation strategy (covered in a separate section).
In total, some common pitfalls include:
Eagerly fetching too much
Cartesian products and excessive cross joins (avoided by lazy fetching over-eager)
Lazy fetching too little
Excessive amounts of N+1 queries (avoided by join fetching where needed)
Cascading N+1 selects due to entity graph dependencies
Unpredictable behavior / performance (use lazy fetching as a default)
Lazy initialization errors
Accessing lazy-initialized proxies outside of transaction scope (lazy initialize proxies, high test coverage is mandatory)
Conversational state vs transactions
Open-session-in-view (avoid always, use lazy fetching and initialization instead).
Attached vs detached entities vs value objects (no need to read before updating or inserting, use reference loading).
2nd level cache write-through and eviction
Scales read efficiently but add additional complexity, cache inconsistency and eviction challenges (anomalies and stale reads).
Distributed second-level caching is complex, and rarely pays off.
Entity Life Cycle
To understand JPA tuning it helps to first understand the entity life cycle or state model (transient, managed, detached, removed) and the API details.
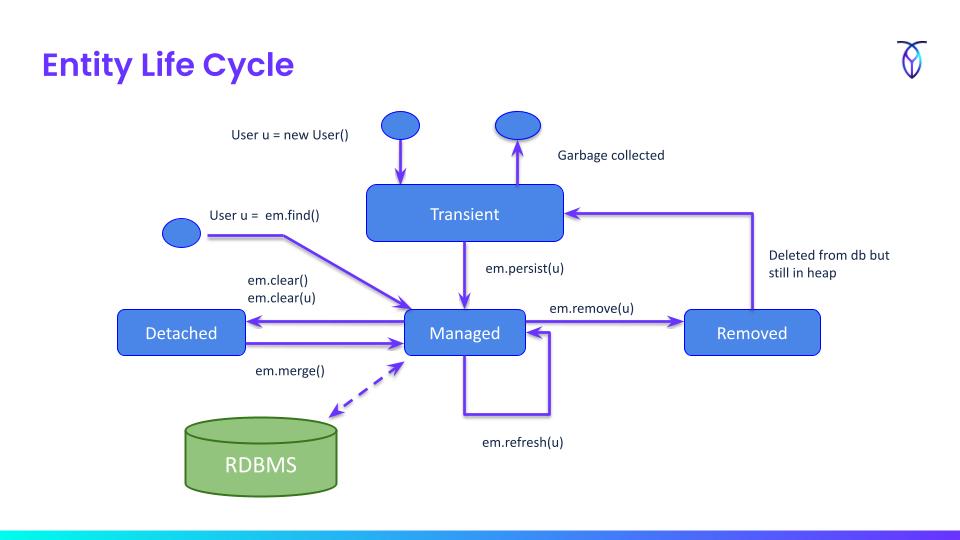
For example, you don’t need to read dependent entities with a SELECT when adding new entities by using getById (in Spring’s JPA repository) over findById. There are low-hanging fruits like that that can make a significant difference in performance.
The entity state model is relevant when entities are passed across the transaction boundary. If a lazy-loaded attribute is accessed without a transaction context, you will get the infamous lazy-loading exception.
Caching
The first-level cache is one good performance reason for using JPA over plain JDBC due to the flush mode at commit time and de-duplications. Hibernate does not send statements over the wire until it’s time to commit and de-duplicate redundant UPDATE’s (if any) before doing so. In contrast to plain JDBC where all statements are sent across the wire.
Illustrations below:



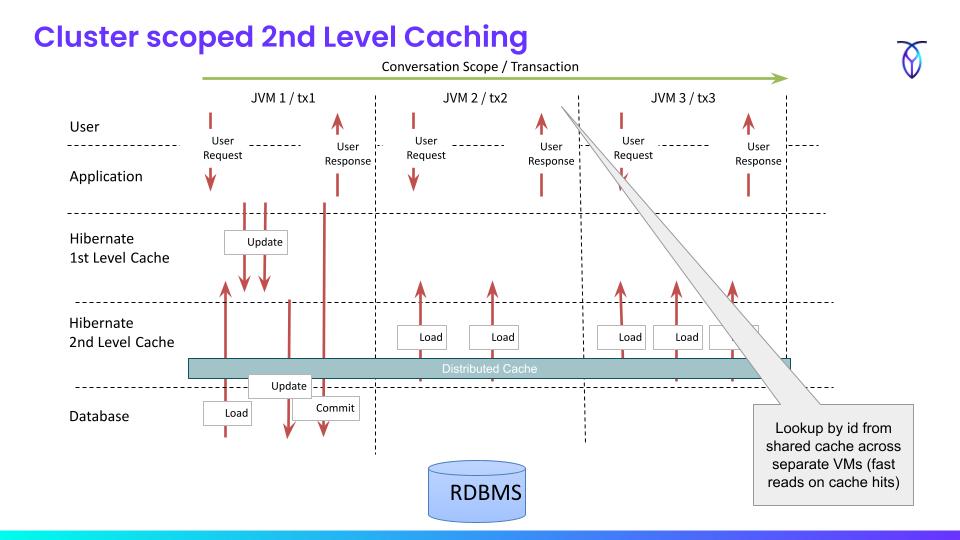
The second-level cache can also use a distributed cache provider, but there are many caveats with that around cache invalidation. Second-level caching strategies are out of the scope of this article.
Batch Inserts and Updates
To optimize write throughput, enable batching and multi-value inserts with the following configuration settings:
hibernate.order_updates=true
hibernate.order_inserts=true
hibernate.jdbc.batch_versioned_data=true
hibernate.jdbc.batch_size=64 // size depends on schema+workload
The reWriteBatchedInserts data source property converts multiple INSERTs to multi-value INSERTs, increasing write performance by 30-40% in most cases once you discover the optimal batch size (schema and workload dependent).
Notice that
reWriteBatchedInsertsparameter is case-sensitive!
See also section 3.2 around ID generation and its impact on batch INSERTs.
Example code:
@Bean
public HikariDataSource hikariDataSource() {
HikariDataSource ds = properties
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
ds.setAutoCommit(false);
ds.addDataSourceProperty("reWriteBatchedInserts", "true"); // Case sensitive
ds.addDataSourceProperty("application_name", "My App");
return ds;
}
Setting JPA vendor properties programmatically:
private Properties jpaVendorProperties() {
return new Properties() {
{
setProperty(Environment.STATEMENT_BATCH_SIZE, "64");
setProperty(Environment.ORDER_INSERTS, "true");
setProperty(Environment.ORDER_UPDATES, "true");
setProperty(Environment.BATCH_VERSIONED_DATA, "true");
setProperty(Environment.GENERATE_STATISTICS, "true");
setProperty(Environment.LOG_SESSION_METRICS, "false");
setProperty(Environment.CACHE_REGION_FACTORY, NoCachingRegionFactory.class.getName());
setProperty(Environment.USE_SECOND_LEVEL_CACHE, "false");
setProperty(Environment.USE_MINIMAL_PUTS, "true");
setProperty(Environment.FORMAT_SQL, "false");
setProperty(Environment.CONNECTION_PROVIDER_DISABLES_AUTOCOMMIT, "true");
setProperty(Environment.NON_CONTEXTUAL_LOB_CREATION, "true");
}
};
}
Open-Session-In-View
Avoid the open-session-in-view (OSIV) anti-pattern. It violates the principle of least surprise and adds an increasing cost down the road. Rather than taking the OSIV shortcut to overcome the lazy-initialization problem, adopt a suitable fetch strategy and map the entity objects to value objects using resource assemblers when passed over logical boundaries.
Generated SQL
Hibernate generates quite verbose SQL based on the entity mappings and JPA queries (JPQL). It’s important to take a closer look at the generated SQL queries and be observant of things like large table scans and join types. Index joins can for example be avoided by covering indexes and projections.
One method is to use the CockroachDB Console. Another is to enable client-side logging using the DataSource proxy pattern, often more readable than Hibernates internal logging. One popular library for this purpose is TTDDYY which wraps a logging proxy around the data source(s).
private final Logger traceLogger = LoggerFactory.getLogger("SQL_TRACE");
@Bean
@Primary
public DataSource primaryDataSource() {
DataSource ds = hikariDataSource();
return traceLogger.isTraceEnabled()
? ProxyDataSourceBuilder
.create(ds)
.asJson()
.logQueryBySlf4j(SLF4JLogLevel.TRACE, traceLogger.getName())
.build()
: ds;
}
Hibernate Dialect
Enable the CockroachDB Hibernate dialect:
CockroachDB201Dialect (Hibernate JavaDocs)
Build a Spring App with CockroachDB and JPA
Example of application.yml:
spring:
jpa:
properties:
hibernate:
dialect: org.hibernate.dialect.CockroachDB201Dialect
datasource:
url: jdbc:postgresql://localhost:26257/spring_boot?sslmode=disable
driver-class-name: org.postgresql.Driver
username: root
password:
or programmatically:
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory(@Autowired DataSource dataSource) {
LocalContainerEntityManagerFactoryBean emf = new LocalContainerEntityManagerFactoryBean();
emf.setPersistenceUnitName(getClass().getSimpleName());
emf.setDataSource(dataSource);
emf.setPackagesToScan("com.example.app");
emf.setJpaVendorAdapter(jpaVendorAdapter());
emf.setJpaProperties(jpaVendorProperties());
return emf;
}
private JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
vendorAdapter.setDatabasePlatform(CockroachDB201Dialect.class.getName());
vendorAdapter.setDatabase(Database.POSTGRESQL);
return vendorAdapter;
}
3.2 How to generate Identifiers
Choosing the appropriate unique ID strategy is different in CockroachDB than in other single-leader databases. To prevent range and node hotspots from forming, it’s recommended to use IDs that are not sequential like SEQUENCE and the SERIAL pseudo-type.
The JPA entity mappings should reflect the strategy is chosen, which is done through the @GeneratedValue annotation on an @Id column. Given the above, however, the strategy options are a bit more narrow and generating surrogate IDs also has some implications around batching due to how write-behind works in Hibernate.
Problem
You want to know which ID generation strategy works best for performance.
Solution
Unless incremental sequences (still with potential gaps) are preferred or required, use an auto-generated unique ID, preferably UUIDs:
@Id
@GeneratedValue(generator = "UUID")
@GenericGenerator(name = "UUID", strategy = "org.hibernate.id.UUIDGenerator")
private UUID id;
Avoid using the IDENTITY generator strategy because Hibernate disables batch support for entities using it due to how the write-behind cache works:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
If you need to use batch inserts while using generated identity columns, then JDBC is the only real option.
Discussion
JPA supports four different primary key generation strategies:
Auto - The persistence provider (Hibernate) picks the appropriate strategy guided by the configured database dialect and data type of the ID.
Identity - Uses an auto-incremented column. In CockroachDB, you would need to adjust the current Hibernate dialect to use this (see below).
Sequence - Uses a database sequence. It’s supported by CockroachDB but it’s not what you want to use for the best performance.
Table - Simulation of a sequence (legacy - avoid)
In addition, Hibernate supports custom ID generator strategies via @GenericGenerator.
One example is UUIDs that you can then generate client-side and have assigned to the entity:
@Id
@GeneratedValue(generator = "AUTO")
private UUID id;
is equivalent to:
@Id
@GeneratedValue(generator = "UUID")
@GenericGenerator(name = "UUID", strategy = "org.hibernate.id.UUIDGenerator")
private UUID id;
Closely related to primary IDs are non-surrogate, natural IDs. You can also leverage natural IDs like user emails, ISBN numbers for books, SKU codes for products, etc using Hibernates native API:
@NaturalId
private String sku;
Hibernate will then use a few optimizations around caching (and enforce immutability) for these IDs.
Don’t forget to add a secondary index to any natural IDs.
Lastly, if you need to use a real type for primary ID along with the IDENTITY generation strategy, and can live without Hibernate support for batch INSERTs, then a custom dialect is needed:
public class CockroachDB221Dialect extends CockroachDB201Dialect {
@Override
public IdentityColumnSupport getIdentityColumnSupport() {
return new CockroachDB221IdentityColumnSupport();
}
private static class CockroachDB221IdentityColumnSupport extends CockroachDB1920IdentityColumnSupport {
@Override
public String getIdentityInsertString() {
return "unique_rowid()";
}
}
}
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
The generated SQL will then include unique_rowid() in the parameter binding of the INSERTs (column id is primary id):
INSERT INTO account(id,a,b,c) VALUES (unique_rowid(),?,?,?)
However, this disables support for batching and multi-value INSERTs. To get that, the real option is to use JDBC for critical sections. With Spring, using JDBC against JPA/Hibernate entities is quite straightforward when using the SimpleJdbcInsert template:
private SimpleJdbcInsert jdbcInsert;
@PostConstruct
public void afterInit() {
this.jdbcInsert = new SimpleJdbcInsert(dataSource)
.withTableName("t_account")
.usingColumns("balance")
.usingGeneratedKeyColumns("id");
}
@Override
@Transactional(propagation = REQUIRES_NEW)
public void create(List<AccountEntity> accounts) {
MapSqlParameterSource[] parameters = accounts
.stream()
.map(account -> new MapSqlParameterSource()
.addValue("balance", account.getBalance()))
.toArray(MapSqlParameterSource[]::new);
int[] rowsAffected = this.jdbcInsert.executeBatch(parameters);
Arrays.stream(rowsAffected).sequential().forEach(value -> {
if (value != SUCCESS_NO_INFO) {
throw new IncorrectResultSizeDataAccessException(1, value);
}
});
}
3.3 How to optimize static entity mapping
Static entity mapping refers to the JPA and Hibernate annotations used in domain entity objects.
Problem
You want to know how to optimize JPA/Hibernate entity mapping for the best performance.
Solution
- Always use lazy fetching by default, and eager fetching only after close analysis:
@OneToMany(orphanRemoval = true, mappedBy = "transaction", fetch = FetchType.LAZY)
private List<TransactionItem> items;
- Use eager fetching in JPA queries only, not in the entity mappings:
@Query(value = "from Order o "
+ "join fetch o.customer c "
+ "where c.userName=:userName")
List<Order> findOrdersByUserName(@Param("userName") String userName);
Avoid inheritance mapping if possible (performance cost).
Only use field-level annotations for readability.
Use persistence cascades carefully (delete’s in particular).
Avoid mapping ManyToMany associations using java.util.List (use a Set instead).
Don’t expose more state than needed (no automatic getter/setter for everything).
Strive for immutability with @Immutable (disables dirty checking).
Use defensive copies:
return new Date(date) return Collections.unmodifiableList(..)
If entities are not used in remoting/detached state then don’t implement java.io.Serializable.
Avoid business logic in entity objects, move to service/control objects instead.
Discussion
Choosing the appropriate fetch strategy is key to avoiding both the N+1 select problem with excessive lazy-loading and the cartesian product problem with excessive joins.
It’s a spectrum where the extremes are chatty and small SQL statements vs over-fetching at the other end. Finding the optimal balance takes some careful consideration and analysis of the SQL generated by the framework.
One challenge also is that JPA and Hibernate differ in the fetch strategy. Hibernate since version 3 defaults to using only lazy-loading on related entities while JPA keeps the “old” model where X-to-many uses lazy-fetching and X-to-one uses eager-fetching. The solution is to always set the “fetch” property on association mappings to lazy, even when it’s the default.
Example of lazy fetching strategy for en element collection (items to order):
@TransactionBoundary(readOnly = true)
public List<Order> findOrdersByStatus(ShipmentStatus status, int limit) {
Assert.isTrue(TransactionSynchronizationManager.isActualTransactionActive(), "No tx");
List<Order> orders = orderRepository.findByShipmentStatus(status,
Pageable.ofSize(limit)).getContent();
// Lazy-fetch associations using a join strategy
orders.forEach(order -> order.getOrderItems().size());
return orders;
}
@Repository
public interface OrderRepository extends JpaRepository<Order, UUID> {
@Query(value = "select o from Order o "
+ "where o.status=:status ",
countQuery = "select count(o.id) from Order o "
+ "where o.status=:status")
Page<Order> findByShipmentStatus(@Param("status") ShipmentStatus status, Pageable page);
}
@Entity
@Table(name = "orders")
@TypeDef(name = "custom_enum", typeClass = ShipmentStatusEnumType.class)
public class Order extends AbstractEntity<UUID> {
@ElementCollection(fetch = FetchType.LAZY)
@JoinColumn(name = "order_id", nullable = false)
@JoinTable(name = "order_items", joinColumns = @JoinColumn(name = "order_id"))
@OrderColumn(name = "item_pos")
private List<OrderItem> orderItems = new ArrayList<>();
}
@Embeddable
public class OrderItem {
@ManyToOne(fetch = FetchType.LAZY) // Default fetch type is EAGER for @ManyToOne
@JoinColumn(name = "product_id", updatable = false)
@Fetch(FetchMode.JOIN)
private Product product;
}
Conclusion
In this article, we looked at a few JPA and Hibernate mapping optimizations to reduce the effects of workload contention.




