



JPA Best Practices - Explicit and Implicit Transactions
JPA and CockroachDB - Part 1


Introduction
This article is part one of a series of data access best practices when using JPA and CockroachDB. The goal is to help reduce the impact of workload contention and to optimize performance. Although most of the principles are fairly framework and database agnostic, it’s mainly targeting the following technology stack:
JPA 2.x and Hibernate
CockroachDB v22+
Spring Boot
Spring Data JPA
Spring AOP with AspectJ
Example Code
The code examples are available on Github.
Chapter 1: Transactions
This chapter addresses some of the issues often related to transaction management in the application tier.
1.1 How to limit transaction lifetime
Transactions should be relatively short-lived in online transactional databases. It will reduce contention-related lock waits, transaction retries and holding on to expensive resources such as connections longer than needed.
Problem
You want to control or limit transaction lifetime to a bare minimum to reduce lock waits and retries.
Solution
Avoid remote API calls and heavy computations inside the scope of a transactional business method. Decompose each business method so that there’s less work to do in each transaction, which also reduces transaction execution time.
Illustration below:
Limit the transaction scope to include only database operations (1,2)
If a remote call is part of a business transaction, execute it outside of the local database transaction, either before or after (3)
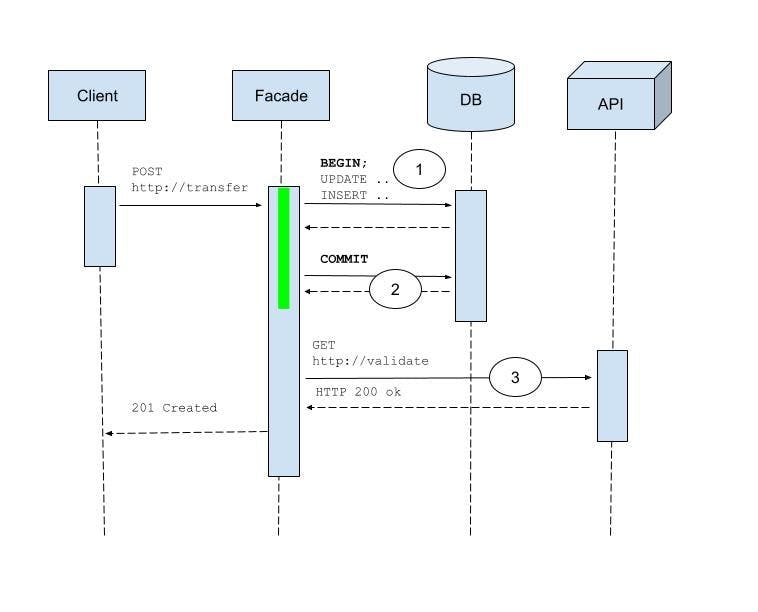
Discussion
It is common to interact with multiple transactional and non-transactional resources in a business method. For example, by reading and writing to a foreign service while also writing to the database by using an explicit transaction.
The sequence diagram below illustrates the happy path of such an interaction flow:
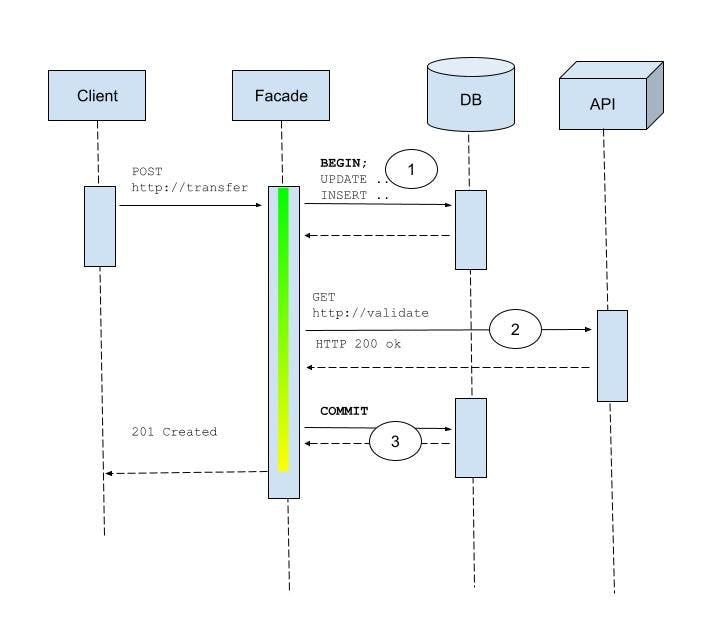
In this example, the remote call (2) can take an arbitrarily long time due to network delays, processing delays or other reasons. While the service facade is waiting for completion, it is also holding (1) resources such as connections and locks in the form of provisional write intents until the transactional method goes out of scope with a commit (3).
In the following sequence diagram, assume there’s a glitch in the remote endpoint:
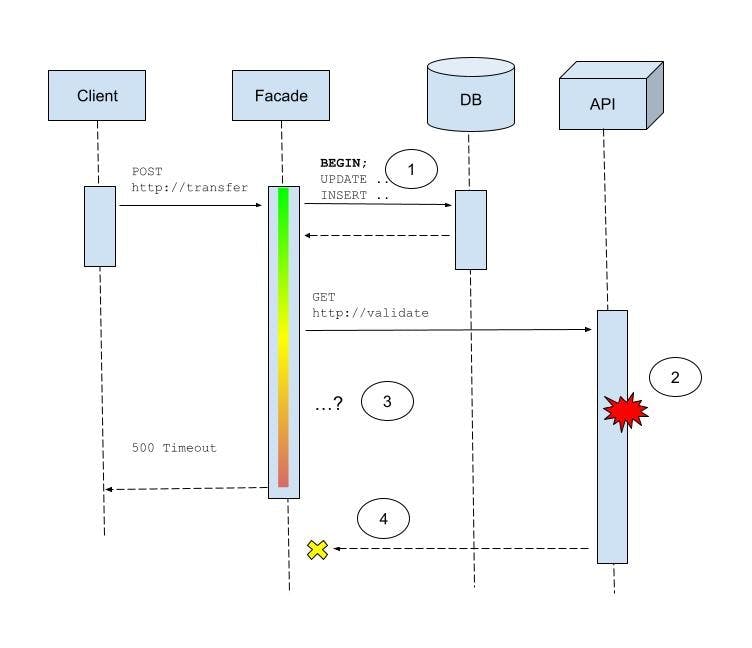
Something is causing a processing delay in the remote service (2) and our facade must now decide what to do. Either wait indefinitely (3) or time out, rollback and signal failure that the validation step did not complete.
One trick to separate database calls from long-running remote calls when using Spring AOP is to have the boundary method do the remote call in a non-transactional scope and then self-invoke the service which then goes via the transactional advice. Alternatively, these parts could be isolated into separate components making it more visible what is going on.
@Autowired
private TransactionServiceExplicit selfRef; // bean with a ref to itself, wrapped in a transactional proxy
@Transactional(propagation = Propagation.NOT_SUPPORTED)
@Override
public void createTransfer_WithPreCondition(TransactionEntity singleton) {
Assert.isTrue(!TransactionSynchronizationManager.isActualTransactionActive(), "Transaction not expected!");
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<String> response
= restTemplate.getForEntity("https://api.host.com/", String.class);
if (response.getStatusCode().is2xxSuccessful()) {
selfRef.createTransfer(singleton); // Starts a new TX here
} else {
throw new IllegalStateException("Disturbance");
}
}
@Override
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void createTransfer(TransactionEntity singleton) {
Assert.isTrue(TransactionSynchronizationManager.isActualTransactionActive(), "Transaction expected!");
jdbcTemplate.update("INSERT INTO t_transaction (" + "id, " + "account_id, " + "amount, " + "transaction_type, "
+ "transaction_status) " + "VALUES (unique_rowid(), ?, ?, ?, ?) RETURNING NOTHING", ps -> {
int i = 1;
ps.setLong(i++, singleton.getAccountId());
ps.setDouble(i++, singleton.getAmount());
ps.setString(i++, singleton.getTransactionType());
ps.setString(i++, singleton.getTransactionStatus());
});
jdbcTemplate.update("UPDATE t_account SET balance=balance+? WHERE id=?", ps -> {
ps.setDouble(1, singleton.getAmount());
ps.setLong(2, singleton.getAccountId());
});
}
1.2 When to use explicit transactions
An explicit transaction is when you have a sandwich structure of a database transaction. First, there’s a BEGIN statement followed by an arbitrary number of SQL statements wrapped with a COMMIT or ROLLBACK.
These markers are typically hidden inside the framework/library code and all you do in Spring for example is declare the transaction boundaries using the @Transactional annotation along with an auto-configured transaction manager.
Depending on the isolation level (I part in ACID), explicit transactions mean you have strong guarantees from the database to safeguard application invariants. CockroachDB only provides serializable (1SR) isolation, which is the highest in the SQL standard.
A quick recap on ACID semantics:
The database guarantees an all-or-nothing behavior where all the operations take effect or none of them (A).
The database guarantees that any state mutation moves the database from one valid state to another valid state and preserves constraints and invariants (C).
The database guarantees that each transaction may execute in parallel while being isolated from the side-effects of other concurrently running transactions similarly as if these would be running serially, one at a time without any concurrency (I=serializable).
The database guarantees that committed writes do not disappear (D).
Problem
You want to know when and how to use explicit transactions.
Solution
Use explicit transactions if you need to group or batch together multiple SQL statements with at least one write and potentially across multiple tables.
One effect of the 1SR isolation level is that explicit transactions are more exposed to transient retriable errors under contending workloads. For example, when multiple concurrent transactions are reading and writing to the same set of keys. It is therefore good practice to capture and retry transient transaction errors client-side in the application tier rather than have it propagate up the entire stack (covered in a separate section below).
Discussion
One typical explicit transaction pattern is to first read some information and then decide to write based on the returned data which must be accurate. The application rule/invariant could state that certain pre-conditions must be met before an update is allowed and the returned values act as a pivot.
Another use case can be that you have repeating reads to the database on the same keys in the same business transactions, or that you are scanning through a larger result set for app-tier computation. If a contending write operation from another transaction comes in at the same time, you don’t want your reads to return dirty, fuzzy or phantom values. Instead, you want to have the appearance that you are the exclusive user of the database for the duration of the transaction and are completely free from interference.
When using JPA and Hibernate, reads have a tendency to cascade to multiple tables depending on the entity mapping and association fetch strategy.
In CockroachDB, reads don’t block any concurrent read or write in other transactions unless FOR UPDATE is used. Reads can however be blocked by provisional writes in another transaction if the read timestamp is older than the write intent timestamp.
Reads are also tracked in a structure called the timestamp cache to guarantee serializability. Whenever a write occurs, its timestamp is checked against the timestamp cache and if the timestamp is less than the timestamp cache's latest value (potentially by a prior read), it’s pushed forward to a later time. Pushing the timestamp will cause additional checks before the transaction is allowed to commit and it may also cause the transaction to restart in the second phase.
In summary, reducing the number of unnecessary cascade reads will reduce the likelihood of other contending transactions' writes to push timestamps and thereby cause restarts.
Using Spring Transactions
Explicit transactions are the default mode of operation in application development frameworks on top of JPA and Hibernate like Spring when using a resource local transaction manager. When a new transaction is created, Hibernate first checks the auto-commit flag and set’s it to false if needed.
One optimization is therefore to set the hibernate.connection.provider_disables_autocommit property to true, which makes Hibernate skip the auto-commit check at the start of a transaction. That should be accompanied by also disabling auto-commit at the JDBC connection pool level (like HikariCP) which is true by default.
Example:
@EnableTransactionManagement
public class MyApplication {
}
Datasource config:
@Bean
public HikariDataSource hikariDataSource() {
HikariDataSource ds = properties
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
ds.setAutoCommit(false); // In combo with Environment.CONNECTION_PROVIDER_DISABLES_AUTOCOMMIT=true
return ds;
}
Persistence config:
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory(@Autowired DataSource dataSource) {
LocalContainerEntityManagerFactoryBean emf = new LocalContainerEntityManagerFactoryBean();
emf.setDataSource(dataSource);
emf.setJpaProperties(jpaVendorProperties());
return emf;
}
private Properties jpaVendorProperties() {
return new Properties() {
{
// other properties omitted
setProperty(Environment.CONNECTION_PROVIDER_DISABLES_AUTOCOMMIT, Boolean.TRUE.toString());
}
};
}
1.3 When to use implicit transactions
An implicit transaction is when you use the auto-commit mode with a single statement. In contrast to explicit mode, there are no BEGIN and COMMIT/ROLLBACK markers but it’s still a transaction in terms of ACID guarantees with a few differences.
In CockroachDB, one is that implicit transactions are retried on the server automatically if necessary, provisioned that the result to the client does not need to be streamed (which depends on data volume). Another is that you can leverage things such as bounded staleness follower read queries.
Problem
You want to know when and how to use implicit transactions.
Solution
Use implicit transactions when you are only reading or don't need to group or batch together multiple SQL statements with at least one write. You can also use “multi-statement” implicit transactions to some extent in the form of modifying common table expressions (CTEs) using plain JDBC. CTEs are currently not supported in JPA.
Discussion
Implicit transactions have the main benefit of being retried automatically on the server if necessary as long as the size of the results being produced for the client, including protocol overhead, is less than 16KiB by default in CockroachDB.
Implicit, auto-commit transactions are the default mode in JDBC connection pools so no special configuration is needed. To use implicit read-only transactions with JPA and Spring, you can use the propagation attributes NEVER or SUPPORTED for annotated methods.
JPA does not support implicit mutating transactions, only read-only queries.
It’s also possible to combine implicit transactions (with or without CTEs) by using JDBC along with JPA repositories. When the transaction manager and Spring data repositories are wired to use JPA, there are some edge cases where these end up being explicit anyway. If you are predominantly using implicit write transactions, then it's likely more optimal to go with auto commit enabled JDBC repositories.
Example:
@EnableTransactionManagement
public class MyApplication {
}
Datasource config:
@Bean
public HikariDataSource hikariDataSource() {
HikariDataSource ds = properties
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
ds.setAutoCommit(true); // just for clarity, this is the default
return ds;
}
Persistence config:
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory(@Autowired DataSource dataSource) {
LocalContainerEntityManagerFactoryBean emf = new LocalContainerEntityManagerFactoryBean();
emf.setDataSource(dataSource);
emf.setJpaProperties(jpaVendorProperties());
return emf;
}
private Properties jpaVendorProperties() {
return new Properties() {
{
setProperty(Environment.CONNECTION_PROVIDER_DISABLES_AUTOCOMMIT, Boolean.FALSE.toString()); // also the default
}
};
Example of a modifying CTE writing to two tables in an implicit transaction:
@Override
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public void createTransfer(TransactionEntity singleton) {
Assert.isTrue(!TransactionSynchronizationManager.isActualTransactionActive(), "Transaction not expected!");
jdbcTemplate.update(
"WITH x AS ( "
+ "INSERT INTO t_transaction ( "
+ " id, "
+ " account_id, "
+ " amount, "
+ " transaction_type, "
+ " transaction_status) "
+ "VALUES (unique_rowid(), ?, ?, ?, ?) RETURNING account_id) "
+ " UPDATE t_account SET balance=balance+? WHERE id=? RETURNING NOTHING",
ps -> {
int i = 1;
ps.setLong(i++, singleton.getAccountId());
ps.setDouble(i++, singleton.getAmount());
ps.setString(i++, singleton.getTransactionType());
ps.setString(i++, singleton.getTransactionStatus());
ps.setDouble(i++, singleton.getAmount());
ps.setLong(i++, singleton.getAccountId());
});
}
1.4 How to use read-only transactions
Read-only queries are safe and idempotent without any client-induced side effects. Read-only queries can also leverage highly scalable features in CockroachDB such as bounded staleness reads.
Problem
You want to know when and how to use read-only transactions.
Solution
Explicit and implicit transactions do not need any explicit read-only declaration. You can also declare explicit transactions as read-only for either safety or clarity, either using a session variable or SET TRANSACTION statement. Default session variables can also be set in the JDBC connection URL.
jdbcTemplate.execute("SET transaction_read_only=true");
or:
jdbcTemplate.execute("SET TRANSACTION READ ONLY");
For all connections using URL options in the application.yml:
url: jdbc:postgresql://localhost:26257/spring_boot?sslmode=disable&options=-c%20default_transaction_read_only=true
driver-class-name: org.postgresql.Driver
username: root
password:
Discussion
One convenient way to set transaction attributes like read-only is through AOP aspects or transaction interceptors. That way you can leverage annotations in the codebase where a policy should be applied rather than using SQL statements.
To use this technique, first, create a meta-annotation to mark the annotated class as @Transactional with propagation level REQUIRES_NEW to indicate that a new transaction is started before method entry. The annotation field then represents the session attributes you want to set.
@Inherited
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
@Transactional(propagation = Propagation.REQUIRES_NEW)
public @interface TransactionBoundary {
boolean readOnly() default false;
}
Then create an aspect with an "around advice" that sets the transaction attribute. Take note of @Order(AdvisorOrder.LOW) which ensures this advice runs in the correct order (last) along with other advice, such as the main transaction advisor that creates the transaction, and any retry advice before that. The chaining order should look something to the effect of:
caller->[retry_advice->transaction_advice->hints_advice]->target
@Aspect
@Order(AdvisorOrder.LOW)
public class TransactionHintsAspect {
protected final Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private JdbcTemplate jdbcTemplate;
@Pointcut("@within(transactionBoundary) || @annotation(transactionBoundary)")
public void anyTransactionBoundaryOperation(TransactionBoundary transactionBoundary) {
}
@Around(value = "anyTransactionBoundaryOperation(transactionBoundary)",
argNames = "pjp,transactionBoundary")
public Object aroundTransactionalMethod(ProceedingJoinPoint pjp, TransactionBoundary transactionBoundary)
throws Throwable {
Assert.isTrue(TransactionSynchronizationManager.isActualTransactionActive(), "Explicit transaction required");
// Grab from type if needed (for non-annotated methods)
if (transactionBoundary == null) {
transactionBoundary = AopSupport.findAnnotation(pjp, TransactionBoundary.class);
}
if (transactionBoundary.readOnly()) {
jdbcTemplate.execute("SET transaction_read_only=true");
}
return pjp.proceed();
}
}
In your service beans, you can then simply set the annotation attribute in the transaction boundary methods:
@TransactionBoundary(readOnly = true)
public Product findProductBySku(String sku) {
Assert.isTrue(TransactionSynchronizationManager.isCurrentTransactionReadOnly(), "Not read-only"); Assert.isTrue(TransactionSynchronizationManager.isActualTransactionActive(), "No tx");
Optional<Product> p = productRepository.findProductBySkuNoLock(sku);
return p.orElseThrow(() -> new IllegalArgumentException("Not found"));
}
1.5 How to retry failed transactions
Applications are more likely to be exposed to transient retry errors for contended workloads in a database that runs transactions with serializable (1SR) isolation guarantees than in more relaxed isolation levels.
Many SQL databases default to weaker isolation levels like read committed (RC) where these retries typically don't manifest. Simply put, this is because lower isolation levels are more permissive at the level of individual read and write operations across concurrent transactions allowing histories that are otherwise prohibited under serializable isolation.
Weak isolation levels expose apps to different anomalies that you need to watch out for. SNAPSHOT isolation for example has the anomaly called write skew which is not always easy to spot.
Other conditions when a transaction can fail are rolling upgrades, node crashes, network issues, leaseholder rebalancing or skewed node clocks. Depending on the error classification (a SQL code) you have an application-level choice to either:
Wait and retry as a convenience for clients to enhance the quality of service
Bail out and have the error propagate up the stack potentially to the client
Problem
You want to know when it’s appropriate and safe to retry failed transactions, and how to implement it.
Solution
As a convenience to the users/clients of your application, always have a client-side (application) retry strategy for explicit transactions in place.
Implicit transactions on the other hand are wrapped in a logical transaction server-side and automatically retried (given some constraints, see the previous section).
Explicit transactions cannot be retried since the database does not know anything about the application semantics and whether it’s safe to retry or not.
In summary:
Classify the error type by SQL code
Apply a recovery strategy with a backoff strategy and timeouts
Expect failures as the norm and not an exception
Discussion
There are many reasons why you would want to have retry logic implemented in any distributed system. A network call from a client to a server (like a DBMS, message broker or service endpoint) can have three possible outcomes:
Success, the client knows the operation took place
Failure, the client knows the operation did not take place
Indeterminate, the client does not know if the operation took place and the result is ambiguous (the 2-generals paradox)
It's generally good practice to always expect failure as a norm rather than an exception. It enhances system robustness, hence a retry mechanism is justified for most interactions over the network.
The decision to retry a failed operation should be guided by first classifying the type of error, whether it is recoverable or not. Repeating the same business request multiple times has a few important considerations like ensuring effectively-once semantics. You typically want to have a single-side effect and idempotent (executing f(x) multiple times has the same effect as executing it once) outcome when a request is repeated for whatever reason.
For example, if sending an email is part of a business transaction alongside writing to the database that can be retried, repeating that whole process would be non-idempotent. Operations that are idempotent with a deterministic input are typically safe to retry. Some operations are naturally idempotent (DELETE / UPDATE in SQL and GET / PUT / DELETE in HTTP) while others may need a durable idempotency key or token used to implement a deduplication strategy, like storing the key along with other writes in a transaction.
In the context of a SQL database like CockroachDB, the first thing to look for is the SQL code of the error message. These codes are sometimes mapped to different exception types depending on the application framework/platform used.
In Spring, for example, there’s a rich DataAccessException hierarchy with two subclasses NonTransientDataAccessException and TransientDataAccessException with derived exception types from there.
The error code 40001 map to concurrency-related transient serialization exceptions, typically a subclass of TransientDataAccessException. The error code 40003 signals an ambiguous result, which can happen at COMMIT or RELEASE SAVEPOINT time. These should be handled the same way as indeterminate network errors when you don’t know if the operation took place.
If there is a response with a SQL code, then use that as a pivot. For 40001 errors, you could just retry the local database transaction with an exponential backoff delay. For 40003 outcomes, if the operation is idempotent (like UPSERTs or DELETEs) then you can also retry. If the SQL statement(s) are non-idempotent, then try to determine at what stage the transaction error occurs and make a judgment call whether it's worth retrying or erroring out, deferring the decision higher up the stack (typically end user/client).
Implementing Retries
Implementing a retry strategy can be done similarly as with read-only transactions mentioned above, only in this case we use and around advice with a cycle that applies exponential backoff on transient errors. Again, take note of @Order annotation and ensure this advice is applied before the main transaction advisor (which defaults to Ordered.LOWEST_PRECEDENCE).
@Aspect
@Order(AdvisorOrder.HIGHEST) // This advisor must be before the TX advisor in the call chain
public class RetryableAspect {
@Pointcut("@within(transactionBoundary) || @annotation(transactionBoundary)")
public void anyTransactionBoundaryOperation(TransactionBoundary transactionBoundary) {
}
@Around(value = "anyTransactionBoundaryOperation(transactionBoundary)",
argNames = "pjp,transactionBoundary")
public Object aroundTransactionalMethod(ProceedingJoinPoint pjp, TransactionBoundary transactionBoundary)
throws Throwable {
// Grab from type if needed (for non-annotated methods)
if (transactionBoundary == null) {
transactionBoundary = AopSupport.findAnnotation(pjp, TransactionBoundary.class);
}
int numCalls = 0;
do {
try {
numCalls++;
return pjp.proceed();
} catch (TransientDataAccessException | TransactionSystemException | JpaSystemException ex) { // TX abort on commit's
Throwable cause = NestedExceptionUtils.getMostSpecificCause(ex);
if (cause instanceof SQLException) {
SQLException sqlException = (SQLException) cause;
if ("40001".equals(sqlException.getSQLState())) { // Transient error code
handleTransientException(sqlException, numCalls, pjp.getSignature().toShortString(),
transactionBoundary.maxBackoff());
continue;
}
}
throw ex;
} catch (UndeclaredThrowableException ex) {
Throwable t = ex.getUndeclaredThrowable();
while (t instanceof UndeclaredThrowableException) {
t = ((UndeclaredThrowableException) t).getUndeclaredThrowable();
}
Throwable cause = NestedExceptionUtils.getMostSpecificCause(ex);
if (cause instanceof SQLException) {
SQLException sqlException = (SQLException) cause;
if ("40001".equals(sqlException.getSQLState())) { // Transient error code
handleTransientException(sqlException, numCalls, pjp.getSignature().toShortString(),
transactionBoundary.maxBackoff());
continue;
}
}
throw ex;
}
} while (numCalls < transactionBoundary.retryAttempts());
throw new ConcurrencyFailureException("Too many transient errors (" + numCalls + ") for method ["
+ pjp.getSignature().toShortString() + "]. Giving up!");
}
}
private void handleTransientException(SQLException ex, int numCalls, String method, long maxBackoff) {
try {
long backoffMillis = Math.min((long) (Math.pow(2, numCalls) + Math.random() * 1000), maxBackoff);
if (numCalls <= 1 && logger.isWarnEnabled()) {
logger.warn("Transient error (backoff {}ms) in call {} to '{}': {}",
backoffMillis, numCalls, method, ex.getMessage());
}
Thread.sleep(backoffMillis);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
Conclusion
We looked at use cases for explicit and implicit transactions and how to reduce the effects of contention. We also looked at implementation strategies for non-intrusive transaction attributes and client-side retries.