





Introduction
This article is part two of a series of data access best practices when using JPA and CockroachDB. The goal is to help reduce the impact of workload contention and to optimize performance. Although most of the principles are fairly framework and database agnostic, it’s mainly targeting the following technology stack:
JPA 2.x and Hibernate
CockroachDB v22+
Spring Boot
Spring Data JPA
Spring AOP with AspectJ
Example Code
The code examples are available on Github.
Chapter 2: SQL Patterns
2.1 How to avoid the read-modify-write pattern
One common design pattern is to read some information from the database, modify it in memory (detached or attached) and write back the changes, at flush or commit time. If you are executing a sequence of operations like that against an overlapping set of keys concurrently in different transactions, then it is subject to transaction serialization conflicts. You can often avoid this pattern by design, but at the same time, it provides a quite convenient mental model.
Problem
You want to know how to avoid read-modify-write to reduce isolation conflicts and improve performance.
Solution
Avoid reading entities for the only purpose of modifying a few attributes and writing back the changes. Instead, execute an UPDATE via reference loading in JPA or an UPSERT via JDBC, potentially with CHECK constraints to protect invariants.
If unavoidable by design, then try moving up the reads to the top and use locks with SELECT FOR UPDATE. In CockroachDB, this will impose key-level locks at read time, which in turn means that concurrent transactions reading or writing the same keys will line up on these locks rather than cause transient rollback errors.
The net effect is that concurrent, contending transactions are ordered around the locks instead of bailing out early with serialization conflict errors. This mechanism was added to CockroachDB to mitigate the effects of contention and not to implement concurrency control like in many other databases.
Discussion
One common use case example is updating bank account balances and/or adding a trace of monetary transactions. In the read-modify-write approach, you would typically read the accounts first to determine whether the balance of the accounts remains positive.
SELECT id,balance,.. FROM account WHERE id in (:ids)
Then you create a record of the change:
INSERT INTO transaction (id,balance,currency,name,..)
(for each account)
INSERT INTO transaction_item (transaction_id,account_id,running_balance,..)
Lastly, you write the balance updates back and the worst case also use in-memory computation:
(for each account)
-- worst case: balance incremented in-memory and then written back
UPDATE account SET balance=? WHERE id=?
-- better: balance increment inlined
UPDATE account SET balance=balance+? WHERE id=?
This sequence of operations is safe and correct but prone to contention and transient retry errors under load.
One easy way or "quick fix" to reduce retries without any major refactoring is to lock the rows being read with a “FOR UPDATE” clause.
Replace the first SELECT with:
SELECT id,balance,.. FROM account WHERE id in (:ids) FOR UPDATE
When a transaction reaches this point and attempts to read, it will hold on to the lock if already held by another transaction rather than proceeding (effective re-ordering).
Note that it doesn’t make contention go away, but limits its effects of it.
A better way is to redesign the whole process. Typically, you want to avoid deciding to write based on a precondition read. Write directly instead and then rely on either database constraints or predicates for invariant enforcement, like negative balances in this case.
Example: Assume we use the same schema as above and add a single allow_negative column that defines if the balance can go negative or not for an account. Then we can use a predicate allowing only accounts based on a precondition to going negative:
UPDATE account SET balance=balance+? WHERE id=? AND (balance + ?) * abs(allow_negative-1)>=0;
In the clear text:
UPDATE account SET balance = balance + -50.00
WHERE id = 1 AND (balance + -50.00) * abs(allow_negative-1) >= 0;
UPDATE account SET balance = balance + -25.00
WHERE id = 2 AND (balance + -25.00) * abs(allow_negative-1) >= 0;
This can be sent as a batch statement. If any of the UPDATEs have zero rows affected rather than one, it means the application should take action.
The full sequence would then eliminate the initial SELECT statement:
(1) INSERT INTO transaction (id,balance,currency,name,..);
(2) INSERT INTO transaction_item (transaction_id,account_id,running_balance,..);
(3) UPDATE account SET balance=balance+? WHERE id=? AND (balance + ?) * abs(allow_negative-1)>=0;
We now eliminated the initial select-for-update read operation while still preserving invariants.
Example:
@Override
public void updateBalances(List<Pair<UUID, BigDecimal>> balanceUpdates) {
int[] rowsAffected = jdbcTemplate.batchUpdate(
"UPDATE account "
+ "SET "
+ " balance = balance + ?,"
+ " updated = clock_timestamp() "
+ "WHERE id = ? "
+ " AND closed=false "
+ " AND (balance + ?) * abs(allow_negative-1) >= 0",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Pair<UUID, BigDecimal> entry = balanceUpdates.get(i);
ps.setBigDecimal(1, entry.getRight());
ps.setObject(2, entry.getLeft());
ps.setBigDecimal(3, entry.getRight());
}
@Override
public int getBatchSize() {
return balanceUpdates.size();
}
});
// Check invariant on neg balance
Arrays.stream(rowsAffected)
.filter(i -> i != 1)
.forEach(i -> {
throw new IncorrectResultSizeDataAccessException(1, i);
});
}
Another approach when dealing with the R-M-W pattern is to use optimistic locking. When reading, you also grab a version number for the entities and then use that version at write time like a compare-and-swap operation. Under serializable isolation, however, optimistic locking does not add value in terms of being more permissive from a concurrency standpoint.
Optimistic locking generally works better at the journey level where a series of independent local transactions are used as part of a wider business process. In that scenario, you typically read entities and return the data in a detached entity state or through value objects. There is user “think time” added before writing back the changes and reattaching the entities to a new persistence context in a separate transaction. As a rule of thumb, whenever “user thinking time” is part of a business transaction, use separate transactions rather than hold on to a single serializable transaction for an arbitrary amount of time.
2.2 How to use follower reads
Follower reads in CockroachDB are time travel queries that enable point-in-time reads, meaning reading committed data at a specified timestamp in the past (at least 4.8 seconds). In CockroachDB, time travel queries are possible within the bounds of MVCC GC TTL, which is 25 hours by default (configurable).
Problem
You want to understand the implications of using follower-read queries.
Solution
Use follower reads when the returned data does not need to be authoritative and can be slightly stale. For example, when reading information for visualization or display.
One use case could be API endpoints that mainly provide informative data that is not used for decision-making and therefore don’t need to be authoritative. Other use cases could be semi-analytical, where the results are used for reporting at a given timestamp.
For example:
Reading user profile data, loyalty points, and transaction history for user display.
Reading account balance(s) for display or snapshot reporting
In contrast, a typical read-modify-write sequence may need to base the modification and write parts on authoritative and non-stale data to safeguard business invariants, in which case follower reads should be avoided.
Discussion
There are two classes of follower reads in CockroachDB, strong and stale follower reads. This section refers to exact staleness reads, where reads are served from the nearest replica to a gateway node.
Reads are normally served by the leaseholder replica of a range, which is the authoritative node currently holding the range lease. If the gateway (node receiving a request from an application) is also the leaseholder for the range(s) accessed, then that’s a fast-track path. If not, read requests are forwarded to the leaseholder node and then returned to the gateway.
Exact staleness reads can be served from follower replicas, given that the read timestamp is sufficiently in the past to qualify (4.8 seconds). This is helpful for contended workloads with interleaved reads and writes against the same keys causing transaction conflicts (and retries).
Because follower reads tolerate older data in the past, these reads do not have to wait for provisional writes, or conflict with concurrent write transactions that otherwise may need to push the timestamp forward, yielding a higher risk for retries.
How reads are served
Normal SELECT:s will always go to the leaseholder replica of the ranges. Follower reads using AS OF SYSTEM TIME with a timestamp sufficiently in the past go to follower replicas, otherwise to leaseholders.
Example of a follower-read query going through a load-balancer (LB) to either the leaseholder or follower replica for a single range:
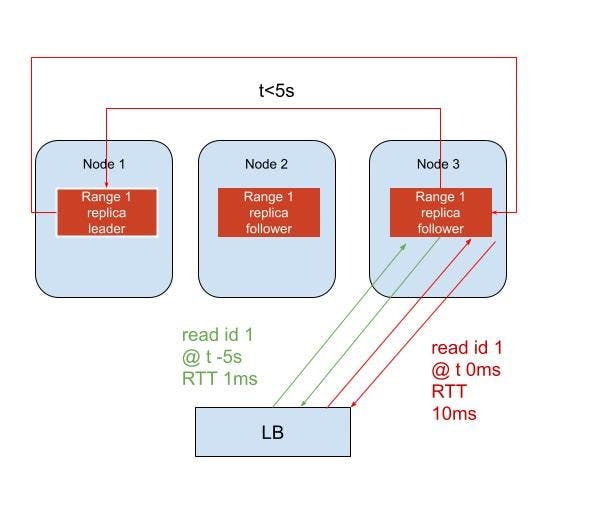
In terms of implementation, follower reads can be implemented using AOP and a "before" advice.
@Aspect
@Order(AdvisorOrder.LOW)
public class FollowerReadAspect {
@Autowired
private JdbcTemplate jdbcTemplate;
@Before(value = "@annotation(followerRead)", argNames = "followerRead")
public void beforeFollowerReadOperation(FollowerRead followerRead) {
if ("(exact)".equals(followerRead.staleness())) {
Assert.isTrue(TransactionSynchronizationManager.isActualTransactionActive(), "Exact staleness reads must use explicit transactions");
jdbcTemplate.execute(
"SET TRANSACTION AS OF SYSTEM TIME follower_read_timestamp()");
} else {
Assert.isTrue(!TransactionSynchronizationManager.isActualTransactionActive(), "Bounded staleness reads must use implicit transactions");
jdbcTemplate.execute(
"SET TRANSACTION AS OF SYSTEM TIME with_max_staleness('" + followerRead.staleness() + "')");
}
}
}
@Inherited
@Documented
@Target(ElementType.METHOD)
@Retention(RUNTIME)
public @interface FollowerRead {
/**
* @return use time bounded or exact staleness (default)
*/
String staleness() default "(exact)";
}
2.3 How to optimize JPA queries
Problem
You want to know how to optimize JPA/Hibernate queries for the best performance.
Solution
General performance hints:
Always use prepared statements in JPQL
Use query projection when loading entities (avoiding star projection)
Use pessimistic locking (FOR UPDATE) in contended read-modify-write workloads to reduce retries
Read-only transactions can be made implicit by not disabling auto-commit
Avoid limit/offset pagination since it results in full scans (use keyset pagination instead)
Reduce roundtrips by reference loading dependent entities (avoids lookup of the parent entity)
EntityManager.getReference(..)orJpaRepository.getReferenceById(..)
Discussion
Hibernate is designed as an abstraction layer around the database and as such is pretty good at hiding the SQL from the developers. This is not always a good thing for performance and makes it more difficult to leverage certain features like CTEs.
When tuning for query performance, always check the generated SQL and strive for a high test coverage when optimizing the lazy-loading strategy.
It’s also fine to combine JPA with JDBC in critical sections to leverage certain features such as CTEs that are unsupported in JPA. There are good alternatives to Hibernate as well that are closer to SQL, such as JooQ, MyBatis and QueryDSL.
Conclusion
in this article, we looked at a few SQL patterns and Hibernate optimizations to reduce the effects of workload contention.