



Photo by Kelly Sikkema on Unsplash
Multi-region Deployments with CockroachDB - Part 1
Performance and availability characteristics when using the Zone level survival goal


Overview
This article is an introduction to the high-availability and multi-region capabilities of CockroachDB, with focus on zone level survival, which is also the default mode.
First, let's take a closer look at how high-availability works in CockroachDB.
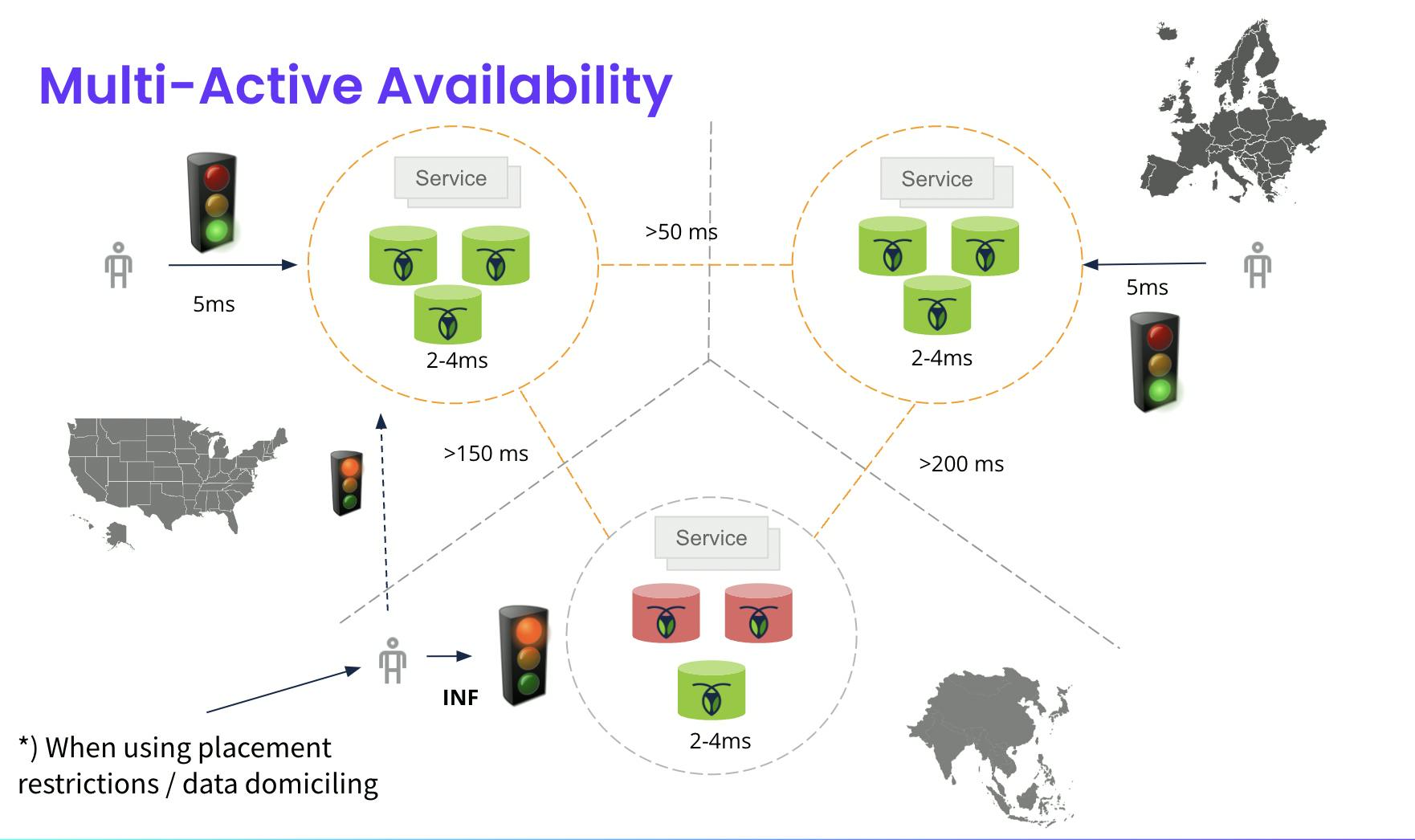
Multi-Active Availability
The high-availability (HA) model that CockroachDB uses is referred to as multi-active.
At a high-level, multi-active can be seen as an evolution over a more traditional active/passive and active/active paired models for disaster recovery. It’s based on the principle that it's better from an HA standpoint to design zone and regional fault-tolerance into the system (end-to-end) and expect failures as the norm rather than an exception.
It's made possible by the consensus based replication model and strong consistency properties of the database. This effectively enables transparent load-balancing and re-routing cross region boundaries without having to consider traffic affinity rules, replication delays or risks of asynchronous replication.
When you build a service with business rules enforced by the stateful tier, you can rest assured that these rules are not violated because of the deployment topology used. This takes a lot of burden away from app developers to worry about transactional integrity and consistency and instead pushes these concerns down to the stateful tier.
One common understanding is that any larger distributed systems is in a constant state of failure, so why not embrace the fact and design for it. In this regard, keeping the business processing layer stateless and the stateful tier multi-active will take you a long way:
By contrast, failover-based HA models are typically based on the opposite; assuming things will not fail and if they do, it’s considered "exceptional" events where you need stand-by capacity ready to kick in at short notice.
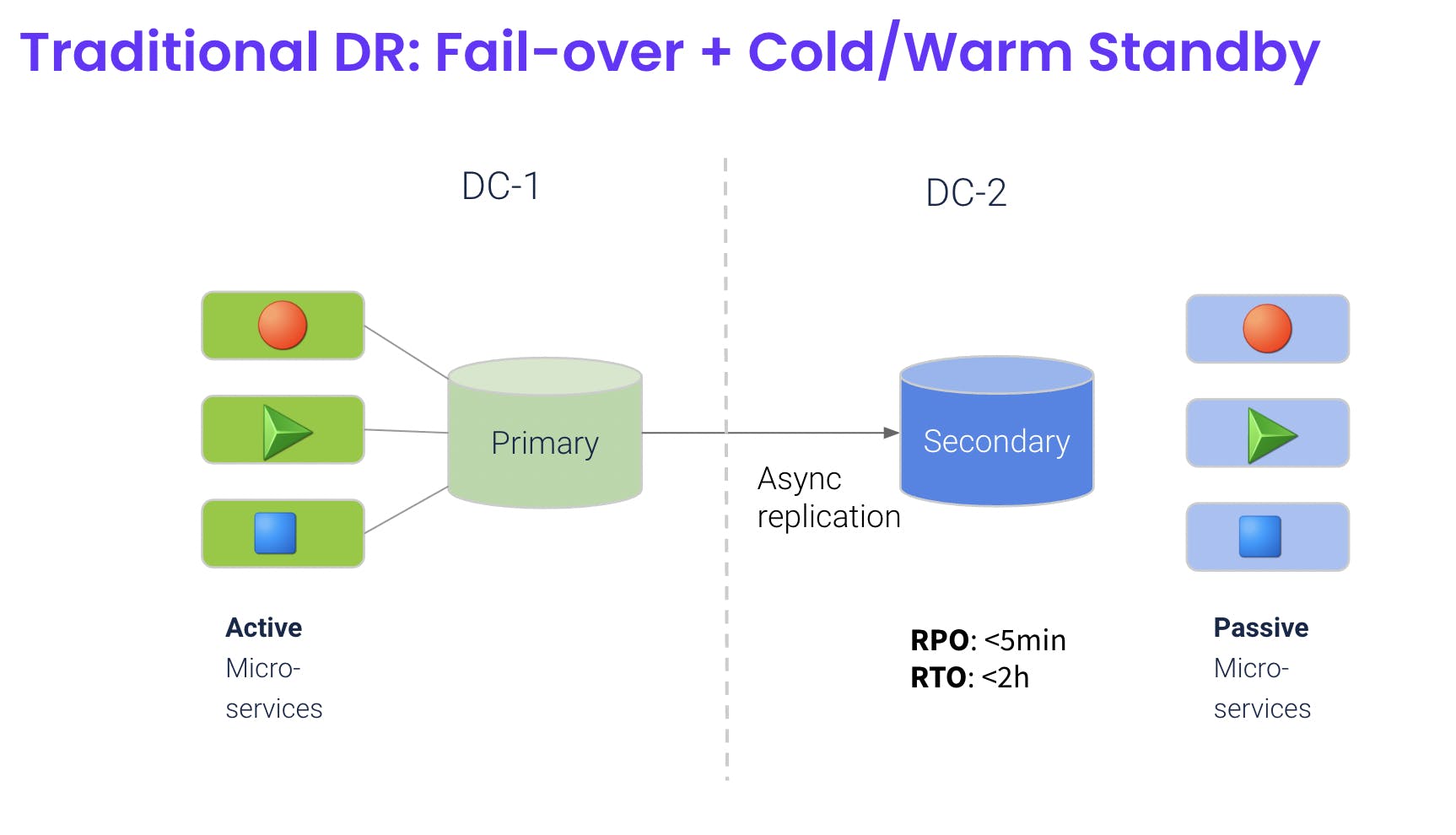
In the meantime, that standby capacity is either sitting idle or is heavily under-utilized. This model also suffers from the drawbacks of asynchronous replication and complexities of later “failing-back” (to use an odd term) and restore normal operation afterwards. Not to mention the difficulties of testing and verifying that it all works in a production environment.
When instead adopting system design principles that allow business services to operate from different sites/locations (cross-region) simultaneously, large blast-radius outages can be handled seamlessly by load balancing and traffic re-routing. Another effect is that resource utilization becomes more cost efficient since you don't need the same hardware footprint in terms of stand-by capacity blowing hot air and waiting for a “disaster” to happen.
One prerequisite for adopting the multi-active model end-to-end, is to have a stateful tier (database) able to act as a control plane with the ability to span different failure domains (regions) while also supporting transactional and strong consistency guarantees towards services/apps.
Cluster Survival Goals
For a CockroachDB cluster stretching across region boundaries, for example us-east-1, europe-west1 and asia-northeast1, it's important to consider the survival goals and read/write latency expectations in each region.
To satisfy different survival, performance and data locality compliance goals for the database, there are different multi-region capabilities such as regional tables, regional by row and global tables.
- Regional tables provide low-latency reads and writes for an entire table from a single region.
- Regional by row tables provide low-latency reads and writes for one or more rows of a table from a single region. Different rows in the table can be optimized for access from different regions.
- Global tables are optimized for low-latency reads from all regions.
Surviving zone level failures
Zone-level survival is the default configuration for a multi-region deployment, where:
- Zone survival is guaranteed (for example, at most 1 of 3 AZs failing).
- Low-latency reads and writes from a single region (primary).
- A choice of low-latency stale reads or high-latency fresh reads from other regions (and high-latency fresh reads is the default).
Surviving region level failures
Region-level survival means that the database will remain fully available for reads and writes, even if an entire region (or a majority of it's AZs) goes down. In this mode, we get:
- Region survival is guaranteed (at most 1 of 3 regions failing, for example)
- Low-latency reads from all regions.
- Higher-latency writes from all regions (at least as much as the round-trip time to the nearest region)
- A choice of low-latency stale reads or high-latency fresh reads from other regions (and high-latency fresh reads is the default).
Zone Level Survival Scenario
Let's look at the following scenario to illustrate zone level survival.
Cluster Configuration
- 3 nodes times 3 regions, nodes diversified across separate AZs (3x3 in total)
Multi-Region Configuration
In this configuration, we use the default zone survival to get:
- Zone level survival, assuming at least 3 zones in one region.
- Low-latency reads and writes from a single region.
- A choice of low-latency stale reads or high-latency fresh reads from other regions (and high-latency fresh reads is the default)
By default, a database is created with ZONE survivability. This means that the system will create a zone configuration with at least three replicas, and will spread these replicas out amongst the available regions defined in the database.
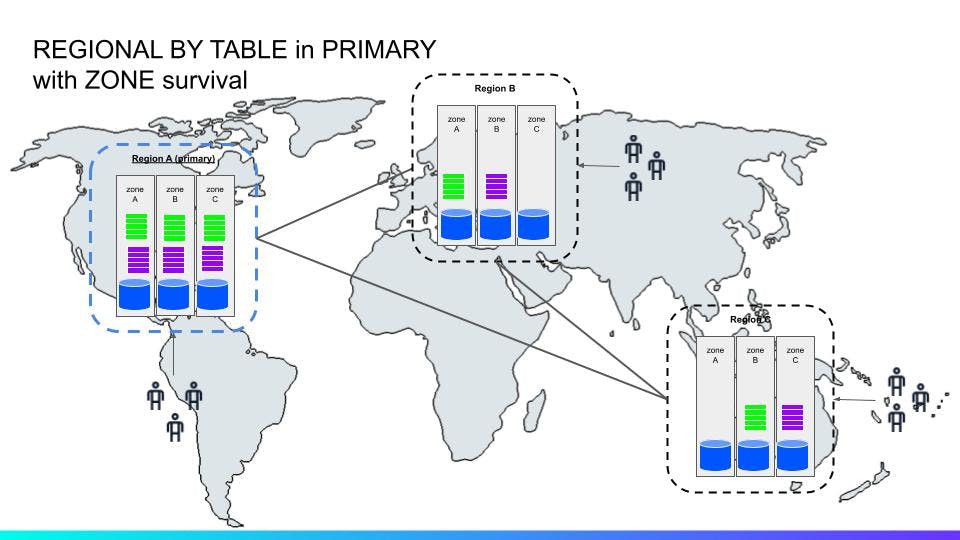
In the figure above (^^) we have a database configured with ZONE survivability, which has placed three replicas in three separate availability zones in the primary region A and two non-voting replicas in the other regions B and C. The colored rectangles represent range replicas (just a massive number of two ranges here for simplicity). In a zone level survival configuration, voting replicas and lease preferences are in a primary region with non-voting replica in others for local stale reads.
This means that writes in the A region will be fast as they won’t need to replicate out of the region, but writes from the B and C region will need to consult the A region. Writes must go through the leaseholder for each range in a transaction and these are only located in the primary region. The system will also place additional non-voting replicas to guarantee that stale reads from all regions can be served locally.
Non-voting replicas follow the Raft log and are thus able to serve follower reads, but do not participate in quorum, with almost no impact on write latencies. A follower read is a historical read at a given timestamp in the past with either exact or bounded staleness guarantees. This allows reads to scale efficiently without having to chase down the leaseholder.
Failure Scenario
Let's look a few failure scenarios.
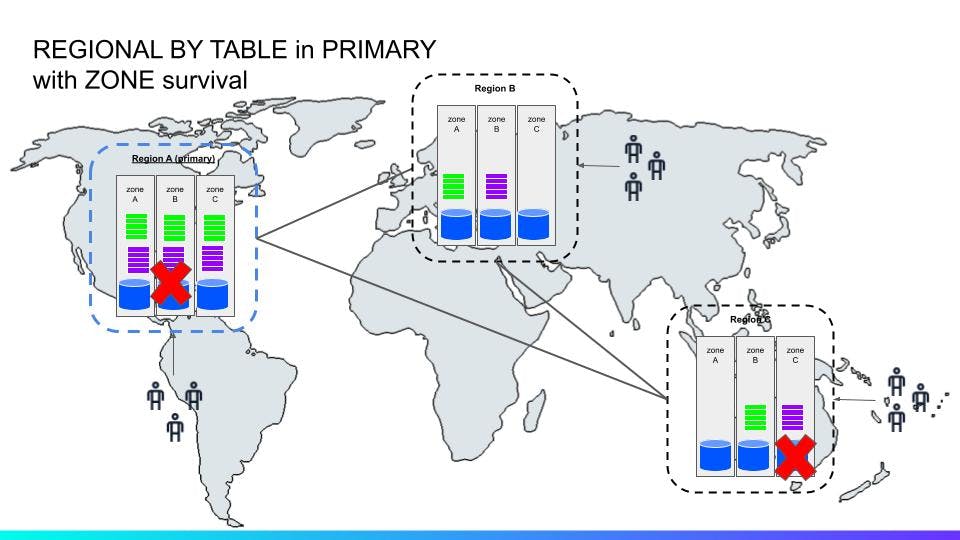
In this (^^) scenario, two nodes are down but in different regions. Only one zones holding the voting replicas are down in the primary region, not affecting forward progress.
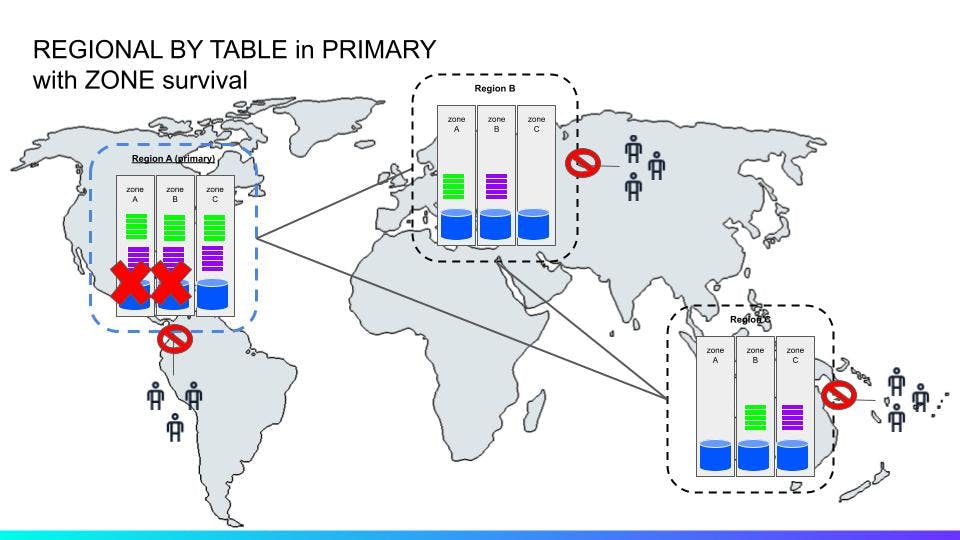
In this (^^) unhappy scenario however, two zones holding voting replicas are down in the primary region. Because the voting replicas and leases are pinned to the primary region in ZONE survival mode, forward progress (on writes) is stopped even though the remaining nodes are reachable.
Using follower reads with bounded staleness however, still provides the ability to serve reads from local replicas even in the presence of a network partition or other failure event that prevents the SQL gateway from communicating with the leaseholder.
Summary
To increase availability beyond zone level, the next step is to define a region level survival goal for a database. Let's contrast zone survival against region survival in a follow-up article. Just to give an overview of how these survival goals differ from a quality attribute standpoint:
| Non-Functional Property | Region Survival | Zone Survival (default) |
| Failures a database can survive | Region (1 of 3 etc) | Zone (1 of 3 etc) |
| Consistency | ACID/1SR, consistent stale reads | ACID/1SR, consistent stale reads |
| Multi-region Configuration | REGION survival, regional by row and global table localities as option | ZONE survival, global table localities as option |
| Performance | Low latency reads in all regions, high latency writes for regional tables | Low latency reads and writes in primary region, low latency stale reads in others |
Regional by row table localities offer both low read and write latency. Global tables offer low latency reads in all regions at the expense of higher write latency.
Conclusion
We looked at CockroachDB's multi-active availability model to survive zone level failures in a multi-regional deployment. By default, the database optimize for reads and writes in a primary region. This comes at the expense of survival. If a majority of zones/nodes in the primary region are offline, then it affects all other regions as well. The next level is region-level survival, which in combination with "super-regions" enable data domiciling to benefit from both low latency reads and writes and region survival.