



Photo by Yosh Ginsu on Unsplash
Multi-region Deployments with CockroachDB - Part 2
Performance and availability characteristics when using the Region level survival goal


Overview
This article is an introduction to the high-availability and multi-region capabilities of CockroachDB, with focus on region level survival. In the first part, we looked into the default zone-level survival goal.
Surviving region level failures
Region-level survival means that the database will remain fully available for reads and writes, even if an entire region (or a majority of it's AZs) goes down. In this mode, we get:
- Region survival is guaranteed (at most 1 of 3 regions failing, for example)
- Low-latency reads from all regions.
- Higher-latency writes from all regions (at least as much as the round-trip time to the nearest region)
- A choice of low-latency stale reads or high-latency fresh reads from other regions (and high-latency fresh reads is the default).
Region Level Survival Scenario
Let's use the following scenario to illustrate region level survival.
Cluster Configuration
- 3 nodes times 3 regions, nodes diversified across separate AZs (3x3 in total)
Multi-Region Configuration
In this configuration, we move from default zone survival to get:
- Region level survival (for example, 1 of 3 regions failing at most).
- Low-latency reads from all regions.
- Higher-latency writes from all regions (due to region survival).
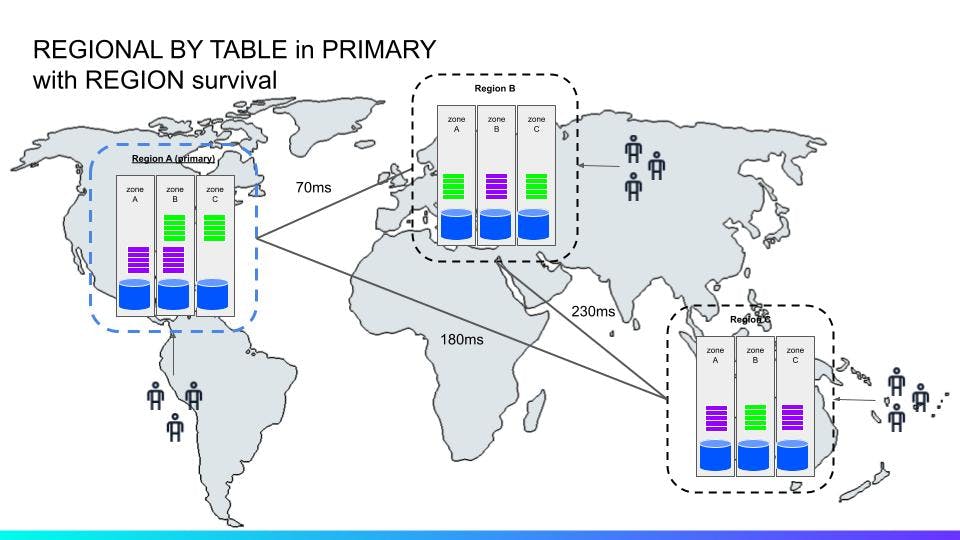
The above ^^ diagram illustrates of a global, 3-region deployment with REGION survival. The colored rectangles represent range replicas.
In this configuration, we changed both survival goals and table localities. Changing the survival goal to REGION increases the replication factor from three to five, which means three out of five replicas must achieve quorum for writes. Reads bypass raft quorums through the concept of leaseholders.
This write overhead is balanced out somewhat by CockroachDB using a parallel, atomic commit protocol that reduce the latency of transactions down to only a single round-trip of distributed consensus.
By placing two replicas in the write-optimized region (in the diagram above, that’s the US region), and spreading the remaining replicas out over the other regions, the end result is that the need for consulting three out of the five replicas to achieve quorum can be handled by consulting only a single region aside from the write-optimized region.
Notable also is that CockroachDB replicates data at the level of ranges (leader + followers forming a raft group) rather than at node or database level. This allows for fine grained data placement controls using both built-in heuristics and operator constraints or restrictions (covered later).
Changing table localities is an optional but very powerful and flexible way to achieve predictable read and write latencies in global, multi-regional deployments. For example, by using REGIONAL BY ROW locality for specific tables with low read and write latency requirements.
For tables with locality REGIONAL BY TABLE, all data in a given table will be optimized for reads and writes in a single region (primary region unless specified) by placing voting replicas and leaseholders there.
This is useful if your data is usually read/written in only one region, and the round trip across regions is acceptable in cases where data is accessed from a different region.
In a multi-region database, REGIONAL BY TABLE IN PRIMARY REGION is the default locality for tables if the LOCALITY is not specified during CREATE TABLE. You can specify which region you wish this data to live in by specifying REGIONAL BY TABLE IN.
For tables with locality REGIONAL BY ROW, individual rows can be homed to a region of your choosing. This is useful for tables where data should be localized for the given application. Think of REGIONAL BY ROW as the "home" region being defined at row level rather than at table level using a hidden or computed column.
A GLOBAL table is optimized for low-latency reads from every region in the database. The tradeoff is that writes will incur higher latencies from any given region, since writes have to be replicated across every region to make the global low-latency reads possible. Use global tables when your application has a "read-mostly" table of reference data that is rarely updated, and needs to be available to all regions.
Failure Scenarios
Below are a few high-level visualizations of different failure scenarios in terms of forward progress from a local application/service standpoint. These scenarios suggest there also being some form of GSLB in place that can seamlessly redirect/balance traffic across the globe.
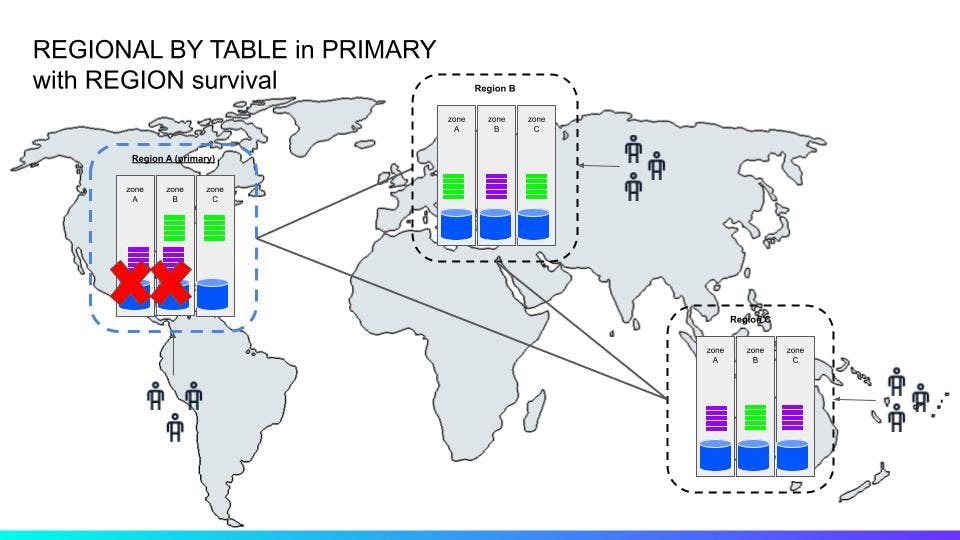
In this (^^) scenario, two zones are down in the primary region. Since there’s still one node available, requests can still be processed in that region, although with a degraded compute/IO capacity of 66%. Eventually, within <10s, the leases for any unavailable ranges (purple color) are transferred to the other two regions.
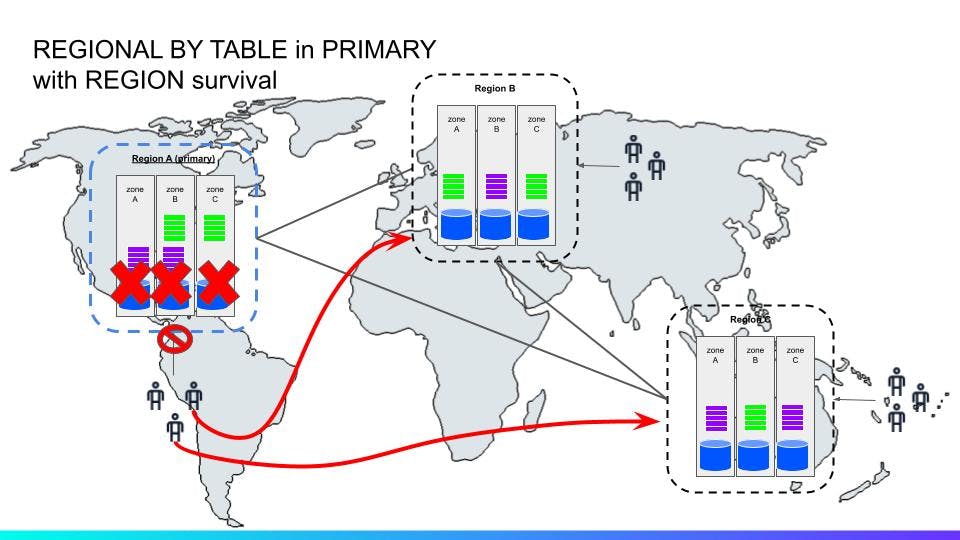
In this (^^) scenario, all three zones are down in the primary region. Requests from clients can quickly be routed to the other regions through some GSLB solution. Eventually (<10s) the leases for any unavailable ranges in the downed region are transferred through a raft operation to any of the other two regions and under-replicated ranges are up-replicated to meet the survival goal (five replicas).
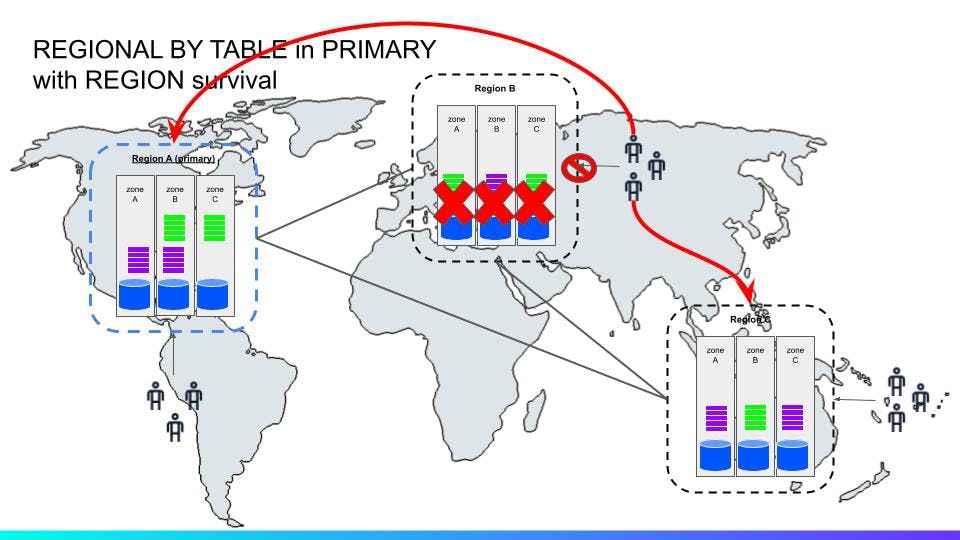
This ^^ scenario is similar to the previous one, only in a different region.
Data Domiciling Option
Data domiciling in CockroachDB allow users to keep certain subsets of data in specific localities. For example: US data only across nodes in the US, EU data across nodes in EU and so forth for compliance and performance reasons. It’s implemented by controlling the placement of specific row or table data using regional tables with the REGIONAL BY ROW and REGIONAL BY TABLE clauses. These placement constraints can be either through restrictions or super regions.
Placement Restrictions
A database can use PLACEMENT RESTRICTED to opt-out of non-voting replicas, which can be placed outside of the regions indicated in zone configuration constraints.
In addition to data domiciling, PLACEMENT RESTRICTED can be used to reduce the total amount of data in the cluster and reduce the overhead of replicating data across a large number of regions. Global tables are not affected by PLACEMENT RESTRICTED and will still be placed in all database regions.
Super Regions
Super regions were introduced in 22.1 primarily to enhance the data domiciling capability. Super regions allow a user to define a set of regions on the database, such that regional and regional-by-row tables located within the super region will have all of their replicas located within the super region.
Super regions take a different approach to data domiciling than PLACEMENT RESTRICTED. Specifically, super regions make it so that all replicas (both voting and non-voting) are placed within the super region, whereas PLACEMENT RESTRICTED makes it so that there are no non-voting replicas.
This means that with super regions, you get to have both data domiciling and region survivability, and region-local latencies on writes. The likelihood of a super-region having a full outage is significantly lower than a single region, but in case that would happen, only access to domiciled data would be be refused. An outage of that magnitude and you'd probably have bigger fish to fry.
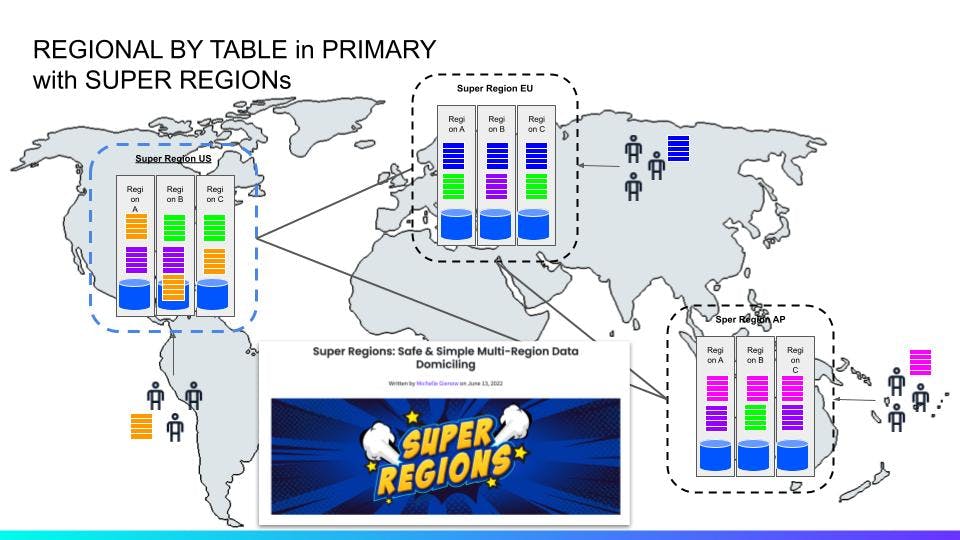
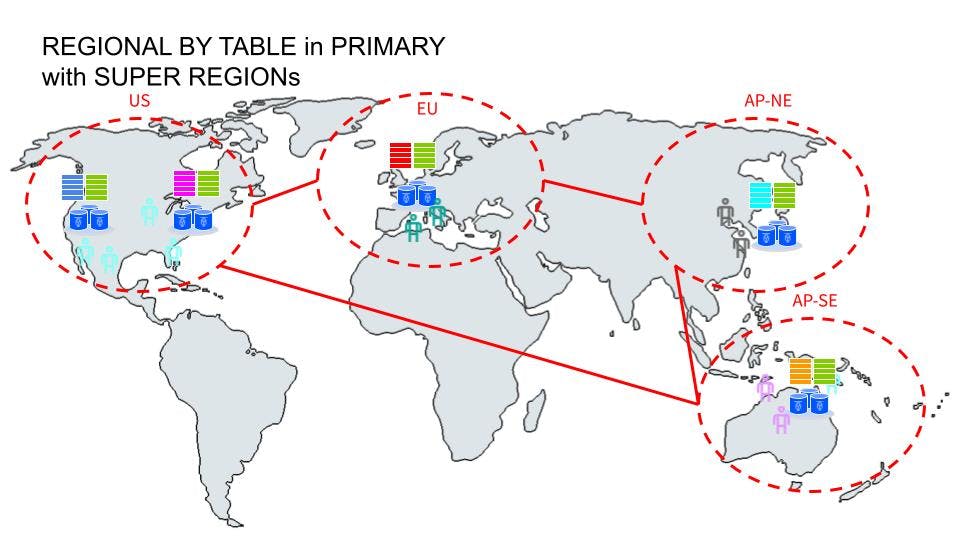
In this ^^ diagram, there are three super-regions with domiciled data in each. In the event of a single region outage in any of these super-regions, it would still allow forward progress for domiciled data. In addition, domiciled data will have all its voting and non-voting replicas pinned to each super-region, allowing writes to reach a quorum without any cross-link coordination.
Configuration Example
To wrap things up, here is a basic cconfiguration example of using regional-by-row. It uses a computed column with the crdb_internal_region to map city names into region names, which is then used for replica placement.
create table users
(
id uuid not null default gen_random_uuid(),
city string not null,
first_name string not null,
last_name string not null,
address string not null,
primary key (id asc)
);
create index users_last_name_index on users (city, last_name);
insert into users (city, first_name, last_name, address)
select 'stockholm',
md5(random()::text),
md5(random()::text),
md5(random()::text)
from generate_series(1, 100);
insert into users (city, first_name, last_name, address)
select 'dublin',
md5(random()::text),
md5(random()::text),
md5(random()::text)
from generate_series(1, 100);
insert into users (city, first_name, last_name, address)
select 'boston',
md5(random()::text),
md5(random()::text),
md5(random()::text)
from generate_series(1, 100);
alter database test primary region "eu-central-1";
alter database test add region "eu-west-3";
alter database test add region "us-east-2";
alter table users
add column region crdb_internal_region as (
case
when city in
('stockholm', 'copenhagen', 'helsinki', 'oslo', 'riga', 'tallinn') then 'eu-central-1'
when city in
('dublin', 'belfast', 'london', 'liverpool', 'manchester', 'glasgow', 'birmingham', 'leeds', 'madrid',
'barcelona', 'sintra', 'rome', 'milan', 'lyon', 'lisbon', 'toulouse', 'paris', 'cologne', 'seville',
'marseille', 'naples', 'turin', 'valencia', 'palermo') then 'eu-west-3'
when city in
('new york', 'boston', 'washington dc', 'miami', 'charlotte', 'atlanta', 'chicago', 'st louis',
'indianapolis', 'nashville', 'dallas', 'houston', 'san francisco', 'los angeles', 'san diego',
'portland', 'las vegas', 'salt lake city') then 'us-east-2'
else 'eu-central-1'
end
) stored not null;
alter table users set locality regional by row as region;
select id,city,region from users;
show ranges from table users;
Conclusion
In this article, we looked at CockroachDB's multi-active availability model to survive region level failures. In addition, using "super-regions" enables data domiciling to benefit from both low latency reads and writes and region level survival. All using a declarative approach with a few SQL statements.