

Multitenancy Applications with Spring Boot and CockroachDB
How to leverage Spring Routing DataSource for multitenancy solutions with CockroachDB


Multitenancy applications use strict bulkheads between different tenant's data within the same application context and instances. This post will demonstrate a common technique for implementing multitenancy with Spring boot by dynamically switching between multiple datasources.
In a previous post, we explored using meta-annotations and AOP aspects to leverage certain features in CockroachDB, such as follower reads and transaction retry's on serialization errors. In summary, this demonstrated a common technique to implement database specific logic in a single place (aspect) and then injecting that at runtime across the codebase in a non-intrusive manner.
Let's explore how the same concept can be leveraged for implementing multitenancy.
Example Code
The code examples in this post are available in GitHub.
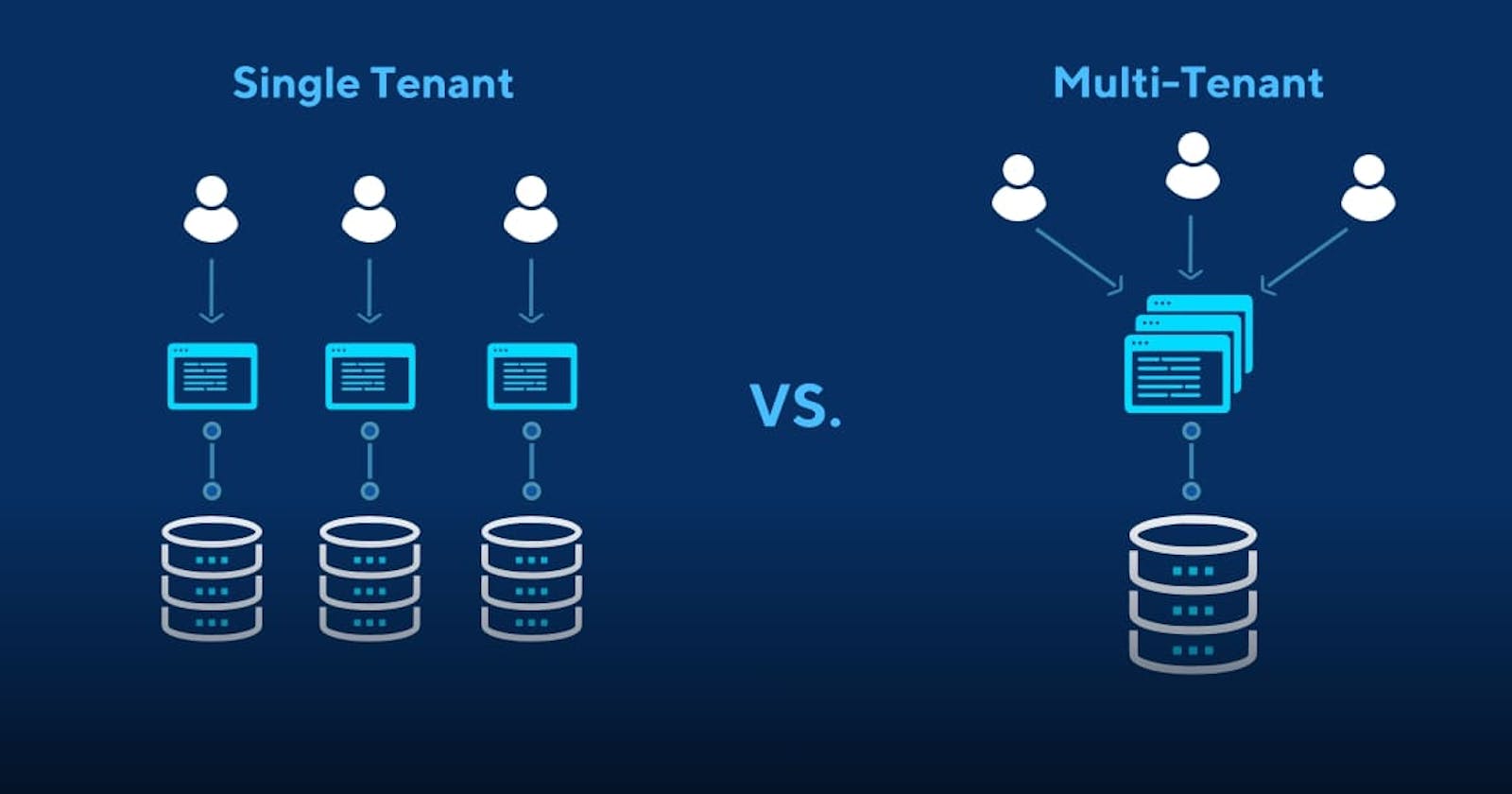
Multitenancy Use Cases
In this context, a multitenant application or service host multiple independent tenants or customers in the same application domain but in separate datas stores. Use case domains could be identity providers, payment providers, iGaming and other types of service or platform providers.
As many different tenants have their own isolated data, any inbound requests needs to be assigned and forwarded to the correct tenant. Rather that implementing this at schema level with tenant id discriminators (which is another option), you bind a tenant ID to the request as part of a header, URI, or JWT token and use that for datasource routing.
From an application standpoint you now have as many datasources as tenants. The normal approach is to have one datasource per application domain and because most frameworks are centred around that, it presents a few challenges when you have hundreds or thousands of tenants. A few challenges being:
- A fool-proof request routing mechanism - there must be a mechanism that performs the actual request routing, as in dynamically switching across multiple transactional datasources based on some criteria such as tenant ID, country, language, a static tag or similar.
- Using declarative transaction management - having multiple configurations for datasources, connection pools and transaction managers is not sustainable, so this all needs to be shared across tenants.
- Database schema versioning and management - automated schema versioning and migrations across many tenants data is key for maintainability and reliable change management.
The goal ultimately is to enable a single codebase to provide the necessary data isolation without having too much code bloat, service duplication and configuration of multiple transaction managers.
Multitenancy Example
Let's put all of this into action with a basic example that will demonstrate:
- how to map datasources to different tenants
- how to implement multitenancy schema management
- how to bind requests / method calls to a tenant
- how to ensure batching and multi-value statements works
The centerpiece for multitenancy in Spring is the AbstractRoutingDataSource. It was introduced long time ago in Spring 2.x and provides a simple mechanism for dynamic datasource selection.
Internally, it just maintains a map of multiple datasources that get switched between depending on a changing context. This context can be pretty much anything, like a tenant ID bound to a thread context, a read-only flag on a transaction boundary marker or a tag denoting a separate read-only or archival database.
Also you don't need to use any XA/2PC transaction manager for this since your'e still just using one transactional resource per business operation.
Let's look a simple example where we have three different databases assigned to different tenants.
Configure Datasource
The first step is to configure the primary routing datasource which its mainly done through the application YAML and TenantDataSourceProperties like below:
@Configuration
public class TenantDataSourceConfiguration {
@Autowired
private TenantDataSourceProperties dataSourceProperties;
@Bean
@Primary
public DataSource primaryDataSource() {
TenantRoutingDataSource routingDataSource = new TenantRoutingDataSource();
routingDataSource.setDefaultTargetDataSource(dataSourceProperties.getDefaultDataSource());
routingDataSource.setTargetDataSources(dataSourceProperties.getDataSources());
routingDataSource.setLenientFallback(false);
return routingDataSource;
}
...
}
The data source configuration which maps to the YAML:
@Component
@ConfigurationProperties(prefix = "roach")
public class TenantDataSourceProperties {
private final Logger traceLogger = LoggerFactory.getLogger("io.roach.SQL_TRACE");
private final Map<Object, Object> dataSources = new LinkedHashMap<>();
public Map<Object, Object> getDataSources() {
return dataSources;
}
public Object getDefaultDataSource() {
return dataSources.get(TenantName.alpha);
}
public void setDataSources(Map<String, DataSourceProperties> properties) {
properties.forEach((key, value) -> this.dataSources.put(
key,
createDataSource(key, value))
);
}
public DataSource createDataSource(String poolName, DataSourceProperties properties) {
int poolSize = Runtime.getRuntime().availableProcessors() * 4;
HikariDataSource ds = properties
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
ds.setPoolName(poolName);
ds.setMaximumPoolSize(poolSize); // Should be: cluster_total_vcpu * 4 / total_pool_number
ds.setMinimumIdle(poolSize / 2); // Should be maxPoolSize for fixed-sized pool
ds.setAutoCommit(false);
ds.addDataSourceProperty("reWriteBatchedInserts", "true");
ds.addDataSourceProperty("application_name", "Multi-Tenancy Demo");
return traceLogger.isTraceEnabled()
? ProxyDataSourceBuilder
.create(ds)
.asJson()
.countQuery()
.logQueryBySlf4j(SLF4JLogLevel.TRACE, traceLogger.getName())
.build()
: ds;
}
}
There are a few additional things in the example above, such as the ProxyDataSourceBuilder to facilitate better SQL trace logging.
Next is a snippet of the application YAML listing the different tenant datasources. In this case alpha, bravo and caesar.
...
roach:
batch-size: 24
datasources:
alpha:
url: jdbc:postgresql://localhost:26257/spring_boot_tenant_alpha?sslmode=disable
driver-class-name: org.postgresql.Driver
username: root
password:
bravo:
url: jdbc:postgresql://localhost:26257/spring_boot_tenant_bravo?sslmode=disable
driver-class-name: org.postgresql.Driver
username: root
password:
caesar:
url: jdbc:postgresql://localhost:26257/spring_boot_tenant_caesar?sslmode=disable
driver-class-name: org.postgresql.Driver
username: root
password:
Last but not least, we will create a custom TenantRoutingDataSource and implement the determineCurrentLookupKey method. This method controls the context switching by returning different datasource IDs.
One highlight is that the lookup key should never be null even if the context is unknown. In that case we default to the first datasource. Returning an unknown or null key will have interesting effects on batching and other parts in JPA/Hibernate since these frameworks do datasource introspection at startup time.
public class TenantRoutingDataSource extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
Tenant id = TenantContext.getTenantId();
if (id == null) { // fallback to default
id = Tenant.alpha;
}
return id.name();
}
}
Multitenancy Schema Management
Flyway is a great tool for database schema versioning and management similar to Liquibase. Using Flyway in a multi-tenancy scenario with many datasources however requires a programmatic approach. The first step is therefore to disable the auto-migration setup in the YAML:
spring:
flyway:
enabled: false
Then it's just a matter of iterating through the datasources and initiate the migration by calling repair and then migrate.
@Configuration
public class TenantDataSourceConfiguration {
@Autowired
private TenantDataSourceProperties dataSourceProperties;
@PostConstruct
public void flywayMigrate() {
dataSourceProperties
.getDataSources()
.values()
.stream()
.map(dataSource -> (DataSource) dataSource)
.forEach(dataSource -> {
Flyway flyway = Flyway.configure()
.dataSource(dataSource)
.load();
flyway.repair();
flyway.migrate();
});
}
}
Binding Requests to Tenants
Binding method calls or requests to specific tenant datasources depends on the use case. For API requests handled in web controllers, it's typically done by using an interceptor that looks for a header field or inside a JWT token.
In this demo however, it's just a tenant ID manually bound to the local thread.
public abstract class TenantRegistry {
private TenantRegistry() {
}
// Thread local variable containing each thread's ID
private static final ThreadLocal<TenantName> threadLocal = new ThreadLocal<>();
public static void setTenantId(TenantName tenantId) {
threadLocal.set(tenantId);
}
public static TenantName getTenantId() {
return threadLocal.get();
}
public static void clear() {
threadLocal.remove();
}
}
Integration Test
To demonstrate how this all ties together, let's use a JUnit5 test along with the spring boot test harness. JUnit5 is the next generation testing framework with good support for integration and functional tests and not just unit tests.
First thing is to create a custom test execution listener that will look for a test method-level annotation and bind the correct tenant ID discriminator to the calling thread:
public class CustomTestExecutionListener extends AbstractTestExecutionListener implements Ordered {
@Override
public int getOrder() {
return 4000 + 1;
}
@Override
public void beforeTestMethod(TestContext testContext) throws Exception {
Method testMethod = testContext.getTestMethod();
TenantScope tc = AnnotationUtils.getAnnotation(testMethod, TenantScope.class);
if (tc != null) {
Assertions.assertFalse(TransactionSynchronizationManager.isActualTransactionActive(),
"Transaction not expected here");
TenantRegistry.setTenantId(tc.value());
}
}
@Override
public void afterTestMethod(TestContext testContext) throws Exception {
TenantRegistry.clear();
}
}
Now it's just a matter of adding the TenantScope annotation to the test method. The following method is expected to store products in the 'alpha' datasource and none of the others.
@Test
@TransactionBoundary
@Commit
@Order(1)
@TenantScope(TenantName.alpha)
public void whenCreatingProductInventory_thenStoreInSingleTenancy() {
Assertions.assertTrue(TransactionSynchronizationManager.isActualTransactionActive(), "TX not active");
List<Product> products = IntStream.rangeClosed(1, numProducts)
.mapToObj(value -> testDoubles.newProduct())
.collect(Collectors.toList());
productRepository.saveAll(products);
}
Full test source here.
Other Use Cases
Multitenancy solutions can have many different forms. This post highlighted the approach of using complete database separation between tenants. In a multi-regional scenairo, this approach could also be used to provide full data isolation per regional level if that is required. Normally however, you would want a cluster to strech logically across multiple regions and thereby provide for higher regional level fault-tolerance.
Another alternative is to implement multitenancy within the schema and database (as initially mentioned) and then leverage geo-partitioning for data isolation, effectively pinning tenant's data to specific nodes in a clsuter. CockroachDB is an ideal choice for that approach given its native multiregion capabilities. Check out this great post on that approach by Andrew Deally: Tenant Isolation with CockroachDB.
Conclusions
Multitenancy using separate isolated datasource is one good implementation strategy that fits very well into Spring Boot. We demonstrated implementing this using the routing datasource, flyway and simple thread-bound tenant IDs.