User defined functions in CockroachDB
How to use UDFs in CockroachDB with JPA

User-defined functions, or UDFs, were introduced in CockroachDB 22.2 as part of a feature family called Distributed Functions.
UDFs are a simpler edition of stored procedures, yet share the same "controversy" around whether or not it's appropriate to push business logic closer to the data, all the way into the database itself. Nevertheless, it's been a highly requested feature to CockroachDB and is now available in preview (meaning it's just a start).
When to use UDFs
A purist would perhaps argue that a service that doesn't manage any state is a function and a service that doesn't process any business logic is a database. Combing both business processing and state/data management and what you get is a service.
These boundaries were strictly defined in the classic service-oriented architecture (SOA) manifesto which later evolved into what we commonly know as the microservice architecture style. Basically by removing all formalism and just describing systems from characteristics such as components, organization around business capabilities, smart endpoints dumb pipes, etc.
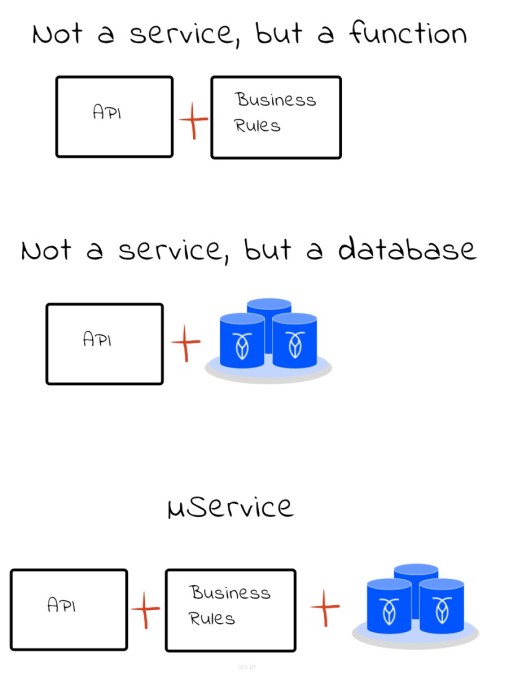
Before deviating too far, there are certainly performance and efficiency benefits of processing close to the proximity of the data since you save network roundtrips.
UDFs are ideal for replacing complicated expressions in queries that would otherwise make application code hard to read, reducing code duplication and promoting consistency. The question is rather when do you draw the line and what is data processing vs business processing logic?
It's easy to forget why these logical and physical tiers exist in the first place: separation of concern. Having most if not all business logic implemented in a stateless middle tier using a high-level language with version control, testing harness, security controls etc does have its benefits. Leave the distributed state problem to the other guy that's much better at it - the database.
How to use UDFs
Once you have overcome the philosophical dilemma of what defines a database, function or service, and are jumping on both feet ready to adopt UDFs, then using them is just a matter of calling functions. Before calling a function, we of course need to have one.
Let's create a simple UDF example in CockroachDB that generates random phone numbers. This could be useful to pre-populate test databases for example.
Here's the syntax:
CREATE OR REPLACE FUNCTION rand_phone_number() RETURNS STRING IMMUTABLE LEAKPROOF LANGUAGE SQL AS
$$
select concat('(',ceil(random()*9+1)::string, ceil(random()*10)::string, ceil(random()*10)::string, ')',
ceil(random()*9+1)::string, ceil(random()*10)::string, ceil(random()*10)::string, '-',
ceil(random()*10)::string,ceil(random()*10)::string,ceil(random()*10)::string,ceil(random()*10)::string)
$$;
Let's break these elements down for completeness.
CREATE OR REPLACE FUNCTION rand_phone_number()specifies that (surprise) we’re creating or replacing a function, and the name of the function will berand_phone_number. The function does not accept any arguments, but could.RETURNS STRINGspecifies that the output will be the STRING datatype.IMMUTABLE LEAKPROOFspecifies the volatility of the function, which in this case, means the function will not mutate/change any data or have other side effects in the database post-execution.LANGUAGE SQLspecifies that the function body will be written in SQL.AS $$select ...$$specifies that the function body will execute the SQL code within the double dollar signs. The semicolon at the end signals the end of the fullCREATE FUNCTIONstatement.
Running it is just like invoking any other built-in function:
select rand_phone_number();
Time: 17ms total (execution 17ms / network 0ms)
rand_phone_number
---------------------
(8910)582-2649
(1 row)
Using Java, this UDF would be the equivalent of:
public static String randomPhoneNumber() {
StringBuilder sb = new StringBuilder()
.append("(")
.append(random.nextInt(9) + 1);
IntStream.range(0, 2).map(i -> random.nextInt(10)).forEach(sb::append);
sb.append(") ").append(random.nextInt(9) + 1);
IntStream.range(0, 2).map(i -> random.nextInt(10)).forEach(sb::append);
sb.append("-");
IntStream.range(0, 4).map(i -> random.nextInt(10)).forEach(sb::append);
return sb.toString();
}
Let's take another example:
create table city ( name string not null, primary key (name) );
INSERT into city VALUES ('new york'), ('boston'), ('washington dc'), ('miami'), ('charlotte'), ('atlanta'), ('chicago'), ('st louis'), ('indianapolis'), ('nashville'), ('dallas'), ('houston'), ('san francisco'), ('los angeles'), ('san diego'), ('portland'), ('las vegas'), ('salt lake city');
CREATE OR REPLACE FUNCTION num_cities() RETURNS INT LANGUAGE SQL AS
$$ select count (1) from city $$;
CREATE OR REPLACE FUNCTION rand_city() RETURNS STRING LANGUAGE SQL AS
$$
select name from city offset ((public.num_cities()::float)*random())::int limit 1
$$;
select rand_city();
Calling a UDF through another is currently not supported in the preview release in CockrocachDB. This was just to add another example.
Calling UDFs using JPA
Calling UDFs is just the same as calling any other function like version():
@GetMapping(produces = {"text/plain", "application/json"})
public String ping() {
return "Hello, youre number is " +
entityManager.createNativeQuery("select rand_phone_number()").getSingleResult();
}
Conclusion
UDFs are a useful mechanism to execute simple data processing functions close to the proximity of the data in the database itself. It eliminates the network roundtrip latency between the application/service tier and the database, and when used appropriately can add performance benefits at the expense of visibility and scattering business logic outside of the bounded context of a business component.




