Create a Ledger Utilizing CockroachDB - Part III - Architecture
Building an accounting ledger with CockroachDB - Architecture

In the third part of a series about RoachBank, a full-stack, financial accounting ledger running on CockroachDB, we will look into the design features and architectural mechanisms used.
Problem Statement
Let's begin by describing what the service does by using a problem statement. A problem statement specifies the system requirements at a high level. Input from business or product owners is critical in composing this statement.
The main characteristics include:
Uses business domain language.
Has clear sentences without jargon.
Describes the project scope.
Specifies the context of the business capability.
Specifies the users/actors of the system.
Specifies known business and technical constraints that are important to consider.
Could serve as the foundation for identifying candidate domain objects (picking nouns).
Example:
The business requires an accounting system to keep track of monetary transactions. Users of the system are internal components that need to manage financial transactions between accounts.
The system must keep track of monetary accounts, transaction history on those accounts and account balances. Each account is associated with an account owner and a base currency. A transaction is the outcome of moving funds between different accounts. A transaction contains several account legs that may involve accounts with different currencies.
The safety mechanism used is the double-entry bookkeeping principle where each transaction must have a zero balance sum of all legs with the same currency. The system must also be able to produce reports of account activities and transactions for external auditors.
Problem statements are very useful when creating new components and for understanding the purpose and meaning of existing ones. Like for this hypothetical accounting ledger.
Architectural Mechanisms
Moving on from the problem domain to the solution domain. Software architectures can be visualized using UML diagrams or the https://c4model.com/ that I find quite useful. But what if you don't have diagrams or don't fancy drawing them?
One approach is to analyze what key architectural mechanisms are needed to implement all the features. Mechanisms are abstractions so when refining these into usable components or tools, you effectively do technology selection appropriate for the business domain (and organisation).
An architectural mechanism represents a common solution to a frequently encountered architectural problem that is not specific to a project or business domain. Quite similar to design patterns.
Implementation mechanisms are typically selected from a technology baseline within a tech organisation. For instance, when persistence is needed (analysis mechanism) and ACID properties are required, then an RDBMS (design mechanism) should be used where CockroachDB (implementation mechanism) is a great choice.
Key architectural mechanisms and realizations in this accounting ledger:
| Analysis | Design & Implementation | Characteristics & Constraints |
| Persistence | RDBMS / CockroachDB & PostgreSQL | CockroachDB is used for all persistence needs. PostgreSQL support is also available for reference. |
| Data Access | ORM / JPA and Hibernate | Hibernate via Spring Data JPA and Spring Data JDBC for reference. JDBC as default. These modes can be switched for performance comparison. |
| Transaction Management | Local Transactions (no XA) | The system uses a local transaction manager for accessing transactional resources such as the database. For database access, a local JPA transaction manager is used. Serializable transaction isolation is required. For eventing, the system uses a mix of Kafka listeners and CDC webhook endpoints for visualization, both with at least once guarantee. |
| Interoperability | Hypermedia API, Websockets, Kafka consumer and webhook endpoint for CockroachDB CDC sinks | Spring Hateoas using HAL+json. Streaming text oriented mesaging protocol (STOMP). Kafka consumer/publisher of CDC event |
| Frontend | Web UI / Thymeleaf template framework, CSS and JQuery, Bootstrap | For visualisation of account activities and system liveness during partial infrastructure disruptions. |
| Observability | Logging / Pull-based HTTP queries | SLF4J + Logback, Spring Actuators, Prometheus endpoint and TTDDYY proxy for JDBC logging |
| Caching | HTTP-level / Client side use of cache headers | HTTP cache headers in REST API. Local Spring cache for heavy reporting queries. |
| Resource Management | Connection Pooling | HikariCP data source. |
| Scheduling | Application Level | Spring built-in cron task scheduling (non-clustered) |
| Versioning | Database Versioning | Flyway |
| Inversion of Control | Application IOC | Spring Boot and AOP aspects for retryable transactions. JDBC driver retries (default) |
| Deployment | Container / Spring Boot | Spring Boot self-contained executable JAR |
| Load Balancing | L4 against the database, L7 against service API / HAProxy | Client-to-service HTTP load balancing is optional. Service to DB load balancing via HAProxy |
| Build | Convention over configuration | Maven 3+, JDK 17 (LTS) at source and target level |
Design Overview
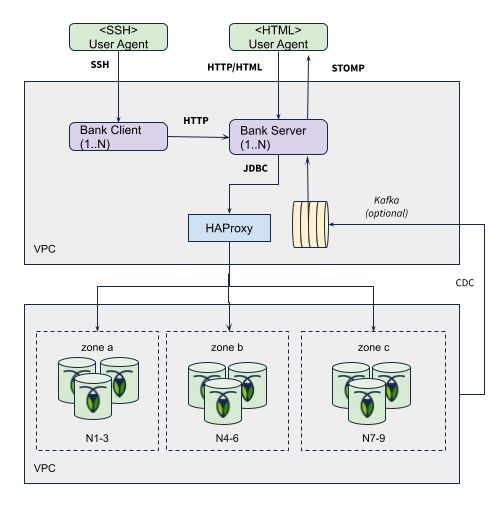
The ledger is based on a common Spring Boot microservice stack using Spring Boot, Spring Data JDBC/JPA, Spring Hateoas, HikariCP, Flyway and more. Kafka as CDC sink is optional for driving account balance push events to the web front-end. The default is just to send the push events after each successful transaction (with an AOP after-advice).
There are two distinct data access implementations; JPA via Hibernate and plain JDBC. Both are included in a single self-contained executable JAR artifact with an embedded Jetty servlet container. It's possible to configure the retry strategy, data access strategy and more through Spring profiles.
It connects to either a CockroachDB cluster or PostgreSQL. When using PostgreSQL, some features are disabled such as follower reads and geo-partitioning.
The bank client issues concurrent requests towards the service API endpoint which in turn reads and writes to the database. When a transfer request is processed, the outcome is a permanent record in history (the ledger) and balance updates on the affected accounts. These balance updates are also pushed to the frontends via websocket STOMP events for visualization.
Architecture Diagram
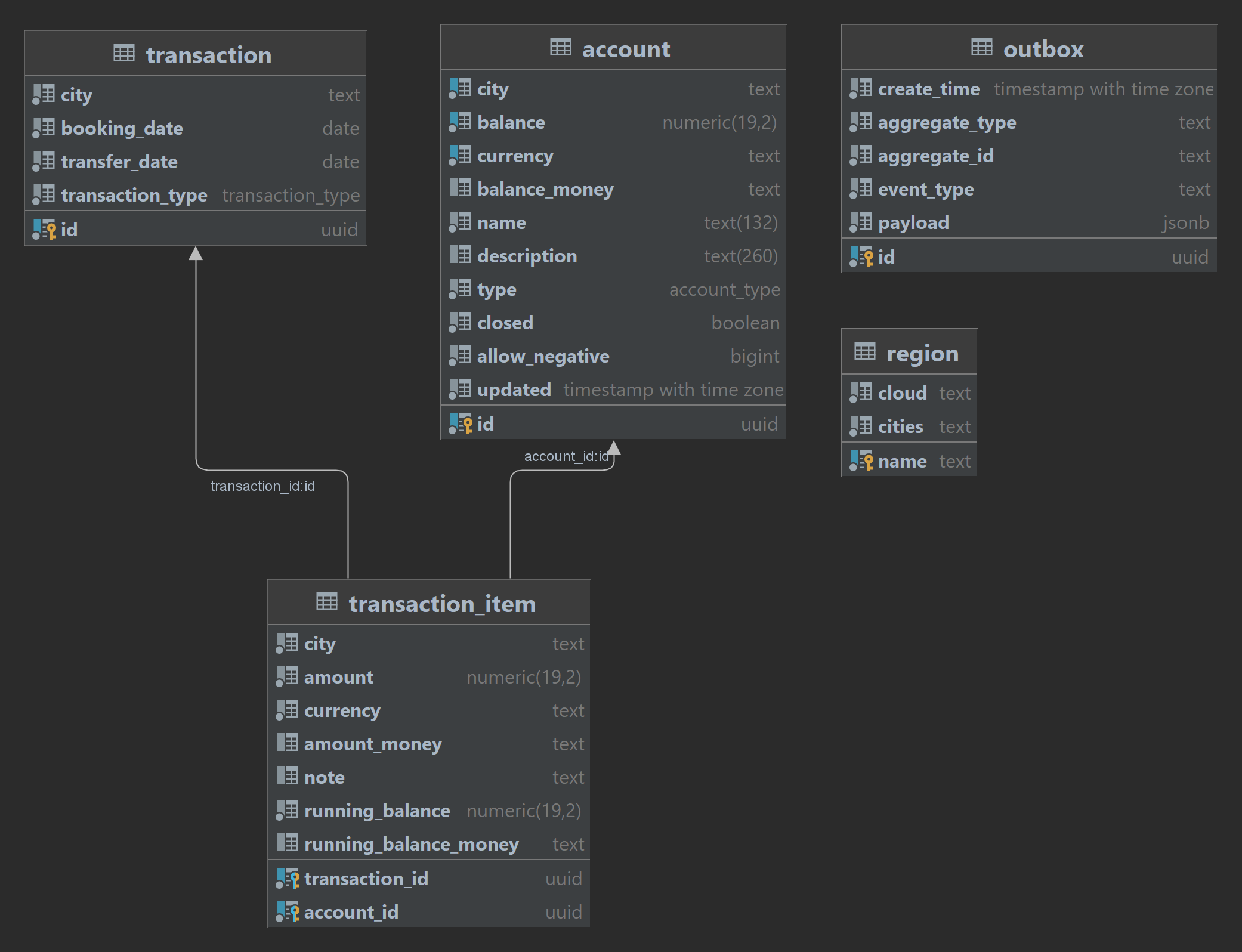
Entity Model
The system uses the following entity model for double-entry bookkeeping of monetary transaction history.
account - Accounts with a derived balance from the sum of transactions
transaction - Owning entity for balanced multi-legged monetary transactions
transaction_item - Association table between transaction and account representing a single leg with a running account balance
region - Static information about deployment regions
outbox - Optional table for showcasing outbox pattern
Main SQL files
Flyway is used to set up the DB schema and account plan during startup time. The schema is not geo-partitioned by default.
Transaction Workflow
Each monetary transaction creates a transaction record (1) and one leg (2) for each account update and also updates the cached balance on each account (3). A CHECK constraint ensures that balances don't end up negative unless allowed for that account (using allow_negative column).
The UPDATE .. FROM (below) with array unnesting is a workaround for the lack of batch updates over the wire. The pgJDBC driver doesn't batch UPDATE statements, only INSERTs up to a given limit using SQL rewrites (aka multi-value inserts).
In the default workflow, the initial balance check on the accounts is redundant since the invariant check is done by looking at the rows affected on the final UPDATE. An UPDATE also takes an implicit lock in the reading part in CockroachDB (configurable) which will reduce retries. In summary, there are no reads involved in the default workflow (not counting the internal read that is part of each UPDATE).
-- (1) header
INSERT INTO transaction (id,city,balance,currency,name,..);
-- (2) for each leg (batch)
INSERT INTO transaction_item (city,transaction_id,..);
-- (3) for each account (batch)
UPDATE account SET balance = account.balance + data_table.balance, updated=clock_timestamp()
FROM (select unnest(?) as id, unnest(?) as balance) as data_table
WHERE account.id=data_table.id
AND account.closed=false
AND (account.balance + data_table.balance) * abs(account.allow_negative-1) >= 0
The actual CHECK constraints:
alter table account
add constraint check_account_allow_negative check (allow_negative between 0 and 1);
alter table account
add constraint check_account_positive_balance check (balance * abs(allow_negative - 1) >= 0);
Transaction Workflow (alternative)
The default workflow yields low contention. There's an alternative workflow designed to provoke more contention to visualize the effects of transient rollback errors and retries. The alternative workflow will perform an initial balance check and optionally use select-for-update (SFU) locks. Without the SFUs, the chance of contention is high. The main benefit of this workflow is that the running balance of the accounts can be stored on the transaction legs.
It's enabled by starting the server with the --roachbank.updateRunningBalance=true option.
-- (1) initial query for all involved accounts (lock is optional)
SELECT .. FROM account WHERE id IN (..) AND city IN (..) /* FOR UPDATE */;
-- (2) header
INSERT INTO transaction (id,city,balance,currency,name,..);
-- (3) for each leg (notice running_balance)
INSERT INTO transaction_item (city,transaction_id,running_balance,..);
-- (4) for each account (batch)
UPDATE account SET balance = account.balance + data_table.balance, updated=clock_timestamp()
FROM (select unnest(?) as id, unnest(?) as balance) as data_table
WHERE account.id=data_table.id
AND account.closed=false
AND (account.balance + data_table.balance) * abs(account.allow_negative-1) >= 0
Transaction Retry Strategy
Any database running in serializable (such as CockroachDB) is exposed to transient SQL errors on contended workloads. These errors are tagged with SQL state 40001 and can be safely retried.
The ledger has three main strategies for performing retries:
Client-side retries using a Spring/AspectJ AOP "around advice" with exponential backoff.
JDBC driver level retries using the CockroachDB JDBC Driver
No retries where transient SQL errors propagate to the client.
The default is client-side retries.
For more details on pros/cons with these different retry strategies, see:
APIs
The ledger provides two main interfaces:
A hypermedia/REST API for request/response-based interactions based on Spring HATEOAS. The shell client (based on Spring Shell) interacts with the ledger through this API.
A WebSocket Streaming API for reactive front-ends, driven via CockroachDB CDC (optional) or synthetic events.
The Hypermedia API is used to view data, create accounts and generate monetary transactions. A typical HTTP client follows the hyperlinks provided by the API to guide through different workflows, such as placing a monetary transaction or browsing through pages of account details. As with any REST API, following hyperlinks is optional. A client can also bind directly to the resource URI:s with tight coupling as a result. The semantics of the endpoints are tied to the link relations rather than the opaque URI:s.
https://en.wikipedia.org/wiki/Hypertext_Application_Language
https://en.wikipedia.org/wiki/HATEOAS
Conclusion
Roach Bank is a financial accounting ledger demo running on CockroachDB and PostgreSQL. It uses an entity model for double-entry bookkeeping and provides two distinct data access implementations. This article discusses an alternative transaction workflow with a balance check and retry strategy for databases running in serializable mode. The retry strategy is handled via Spring/CGLIB proxies with exponential backoff.




